Lineage Is a Graph Problem: Tracing Revenue to Raw Data With PuppyGraph
Introduction
On most data teams, a question as ordinary as “where does Revenue come from” does not have a quick answer. Finding it usually means visiting three places. You open the dbt documentation to locate the model that produces the number, you click through the Unity Catalog lineage view to trace the tables that feed it, and you check a wiki or ask a colleague to confirm what Revenue is meant to represent and which column actually holds it. Provenance lives in one system and meaning lives in another, and a person has to reconcile the two before the answer can be trusted.
This separation is the problem the project addresses. Lineage tools describe where data comes from, but they carry no notion of what a column means to the business. Glossaries and column comments capture meaning, but they cannot traverse a dependency graph. Hand the question to an AI agent with neither of these wired into it, and the agent will answer from its own reasoning, which is acceptable for brainstorming and unacceptable for a question about where a financial number originates.
The work described here joins the two halves. It places business meaning and data lineage in a single graph, allows the full path to be traversed with one query, and lets an AI agent answer the question by reading that graph rather than improvising. The complete source is on GitHub. The sections that follow describe the system, explain the reasoning behind each decision, and set the work honestly against the products that solve adjacent problems.
The system at a glance
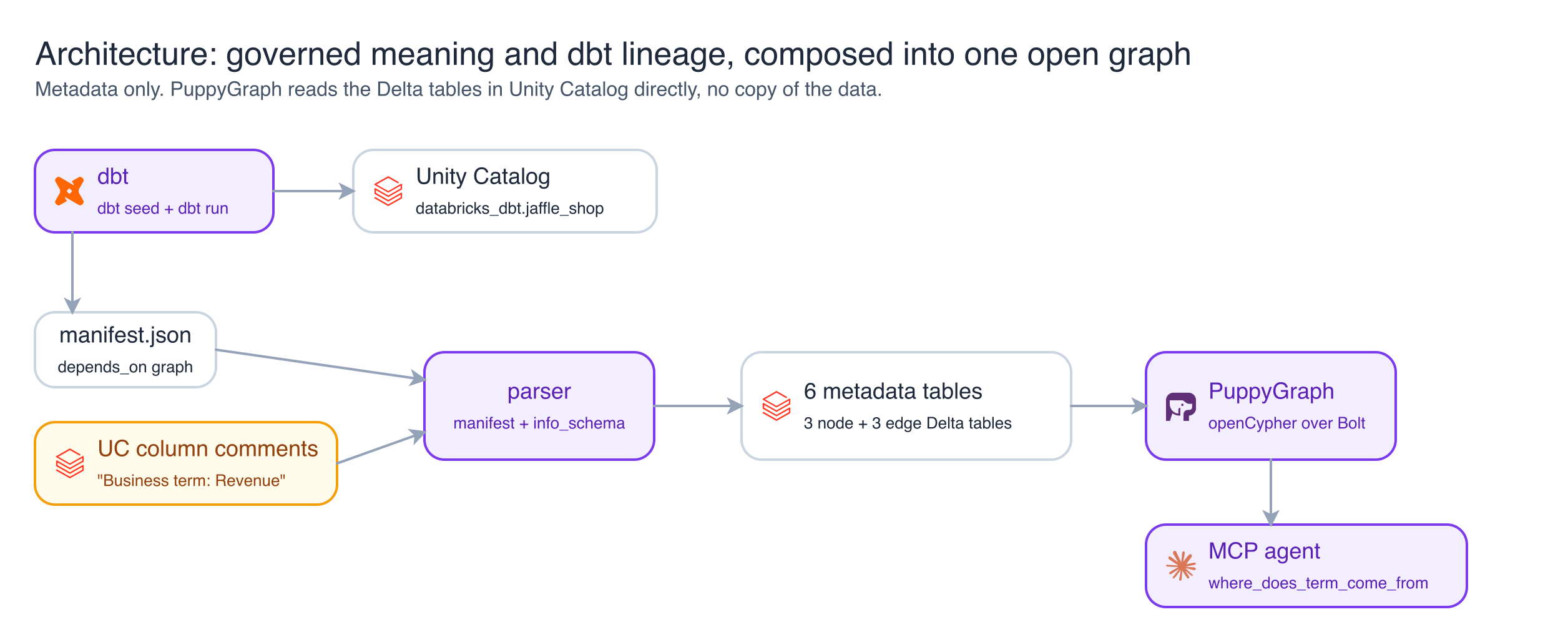
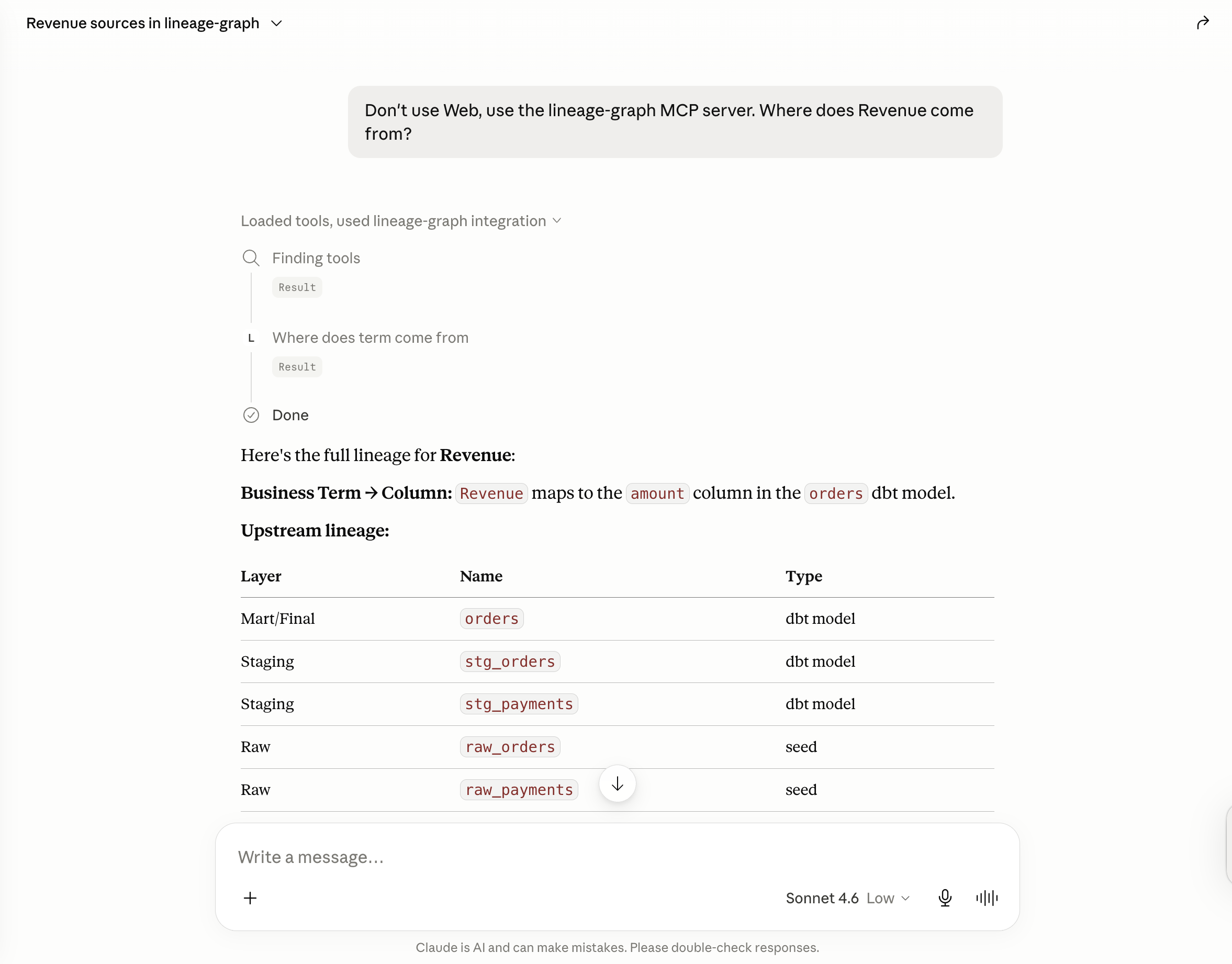
The dataset is the well-known dbt jaffle_shop project, built into Databricks Unity Catalog. Business terms such as Revenue are stored in Databricks as governed column comments rather than in application code. A small parser combines the lineage that dbt produces with those comments and writes the result into a set of metadata tables. PuppyGraph maps those tables into a property graph without copying any data, and a single openCypher query walks from a business term to the raw tables that ultimately produce it.
For Revenue, that query returns the following path:
Revenue -> orders.amount -> orders -> stg_orders, stg_payments -> raw_orders, raw_payments
Reading from the left, Revenue resolves to the column orders.amount, that column belongs to the orders model, and orders is assembled from two staging models, each built in turn from a raw seed. The graph stores metadata alone, meaning model names, business terms, and the relationships between them. At no point does it hold a row of business data.
Building the tables with dbt
The pipeline begins with dbt. Running dbt seed followed by dbt run loads the three raw CSV seeds as source tables in Unity Catalog and builds the staging and final models on top of them, all within the databricks_dbt.jaffle_shop schema. This step is more significant than it first appears, because lineage has no meaning until something has actually built the tables. The raw seeds are the genuine source nodes, and every other node in the graph descends from them.
As part of the same run, dbt writes a file named manifest.json to the local machine. Each model in that file carries a depends_on list, and collectively those lists are the lineage. The valuable property is that dbt generates the manifest automatically during the build. No one writes the dependency graph by hand, so it cannot drift from what was actually constructed.
Recording business meaning in Unity Catalog
Lineage establishes that orders.amount is derived from the payment staging model. It says nothing about orders.amount representing Revenue. That meaning has to be recorded somewhere, and choosing where to record it is the first substantive design decision in the project.
I recorded it in Unity Catalog, as a governed column comment. The comment on orders.amount reads, in full, “Business term: Revenue. Definition: total order value in AUD.” Comparable comments describe Customer Lifetime Value on the customers model and Payment Method Revenue across the four payment columns. The parser reads these comments and extracts the term from each.
The case for this placement is governance. The definition of a business metric belongs in the governance layer, alongside the data it describes, where the people accountable for it can review and own it. It does not belong in a Python file that only an engineer will ever read. The approach is also deterministic, because the term is taken from a comment that a human wrote on purpose, and it is never inferred by a model or guessed from the column name. A more structured implementation could use Unity Catalog tags or a metric view in place of a free text comment, and I mention that alternative deliberately so the decision is visible rather than implied. I kept the comment because it is simple and it conveys the idea without ceremony.
Choosing the lineage source
A reasonable objection arises at this point. Unity Catalog already captures column level lineage, natively and automatically, for every query that runs on Databricks. If the platform records lineage on its own, why involve dbt at all?
The answer has two parts, because dbt performs two distinct jobs here and only one of them overlaps with Unity Catalog.
The first job is building the tables. Unity Catalog lineage does not produce data. It observes execution and records what touched what. A transformation tool is still required to declare that orders is an aggregation over the payment staging model, and dbt is that tool. There is no overlap on this job at all, since dbt creates the graph and Unity Catalog merely watches it form.
The second job is supplying the lineage that the parser consumes, and here the overlap is real. On Databricks, lineage could be read from the native system tables instead of from the dbt manifest. I chose the manifest for three reasons. It is complete the instant dbt finishes, it reads identically whether or not the code runs on Databricks, and it does not depend on query history having accumulated. The last reason is decisive. Unity Catalog lineage is populated from actual query execution, so on a quiet demo with no traffic it would be sparse or empty, whereas the manifest provides the entire declared graph on the first run. In production, with real workloads flowing, Unity Catalog lineage is the more truthful source, because it reflects everything that genuinely ran, including transformations performed outside dbt, and a more advanced version of this project would read from it. For a small and reproducible demonstration, the manifest is the pragmatic choice.
It is worth being explicit that Unity Catalog is the foundation of the project, not a rival to it. The tables reside in it, the business meaning lives in it as comments, the grant that lets PuppyGraph read the data is a Unity Catalog privilege, and the native lineage sits in it as well. The project composes the governed metadata that Unity Catalog already maintains into an open graph. It replaces none of it.
The parser that joins lineage and meaning
The parser is the single point at which lineage and meaning come together, and it is intentionally small. It reads manifest.json and emits the model nodes together with the dependency edges between them. It then connects to Unity Catalog, reads the column comments through information_schema, and parses the governed “Business term: …” convention to recover the terms. Finally, it joins the two sides into six metadata tables: the model nodes, the dependency edges, the term nodes, the column nodes, the term to column edges, and the column to model edges.
Nothing in this step is hardcoded. The terms come from the comments, the lineage comes from the manifest, and the parser only performs the join. I was deliberate about this, because a business term written into the parser would silently undermine the entire reason for governing that term in Unity Catalog.
The graph model and the traversal
PuppyGraph maps the six tables into a property graph built from three node types and three edge types. A Term is measured by a Column, a Column resides in a Model, and a Model depends on another Model. That compact vocabulary is the whole model.
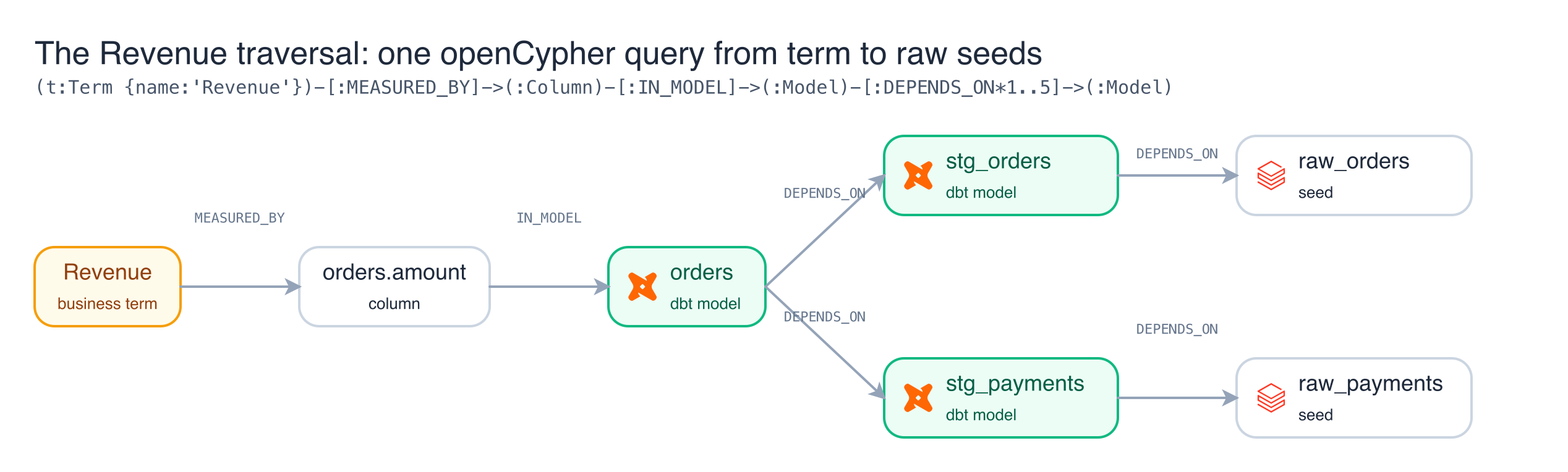
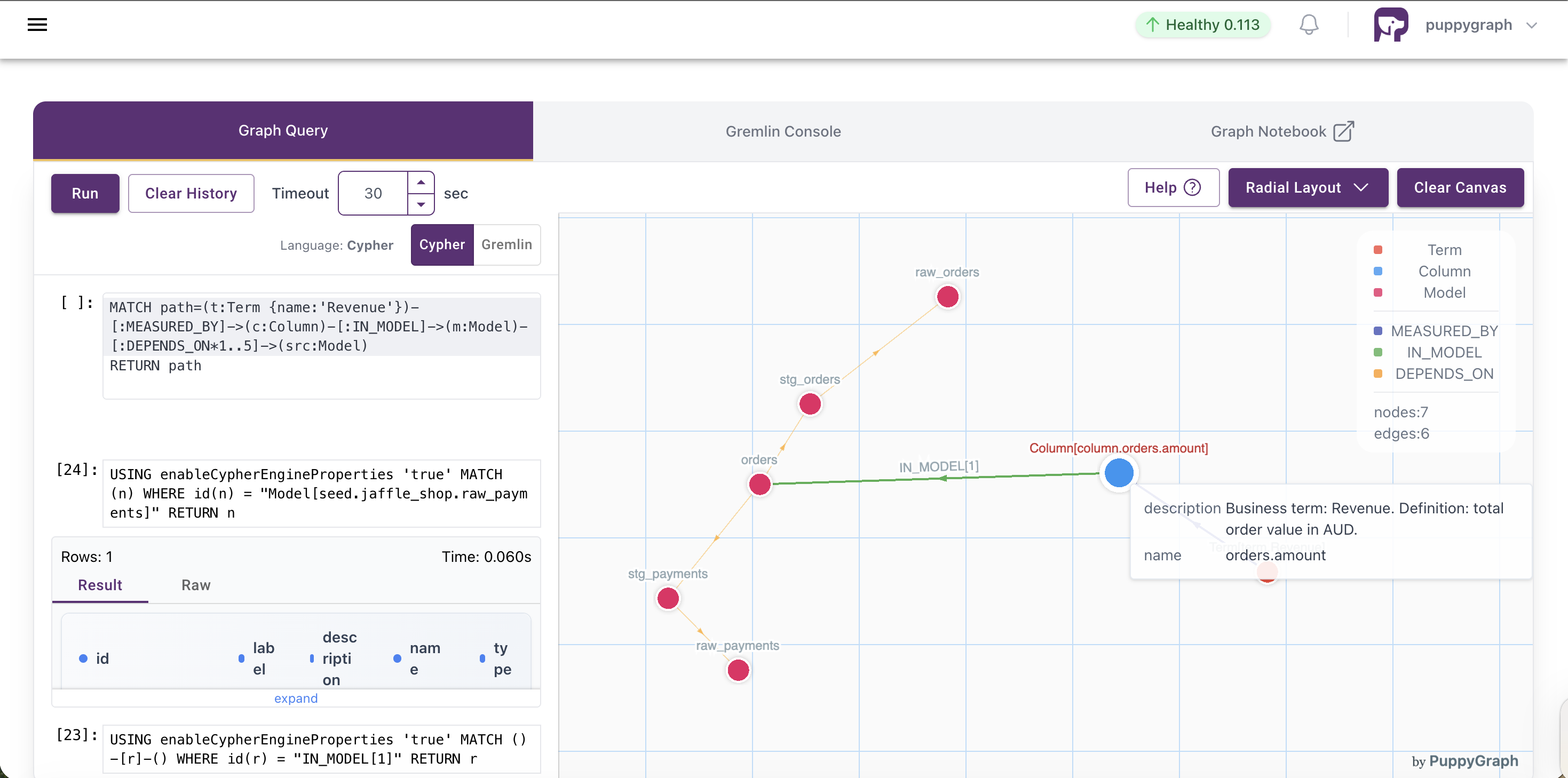
Because PuppyGraph reads the Delta tables in Unity Catalog directly, by way of an EXTERNAL USE SCHEMA grant, there is no second copy of the data and no additional store to reconcile. The graph is a queryable view over tables that already exist. PuppyGraph speaks both the Bolt protocol and Gremlin, and I use openCypher throughout to keep a single query language across the system. The deliverable reduces to one query:
MATCH path = (t:Term {name: 'Revenue'})-[:MEASURED_BY]->(c:Column)
-[:IN_MODEL]->(m:Model)-[:DEPENDS_ON*1..5]->(src:Model)
RETURN path
The expressive part is the variable length traversal, DEPENDS_ON*1..5, which instructs the engine to follow dependency edges through as many hops as are needed to reach the raw seeds. A flat lineage listing cannot express that in a single step, and this is precisely where a graph representation earns its place.
Why the work belongs in a graph engine
There is a fair challenge to make here. With only eight nodes, the dbt manifest could simply be pasted into an AI model with the question of where Revenue comes from, and the model would very likely answer correctly. For a problem this small, PuppyGraph is more machinery than the task requires, and I will not pretend otherwise. The value of a graph engine becomes apparent only once the problem grows.
A production lineage graph is not eight nodes. It spans thousands to millions of nodes across many projects and systems, and a graph of that size cannot be placed in a prompt without the model losing the thread and beginning to guess. A graph engine traverses it deterministically at any scale. More fundamentally, the moment a model is asked to read raw logs and infer the lineage itself, the model has become the lineage engine, which is exactly the failure mode the project sets out to prevent. With PuppyGraph, the path is computed by a query and the model is left only to express it in words. The graph also composes two sources rather than one, answers a family of questions rather than a single one, and always reflects the current state of the tables rather than a snapshot that must be regathered. The demonstration is kept small for reproducibility, but the pattern is what survives at production scale, where pasting logs into a prompt quietly stops working.
Grounding an agent in the graph
The final component connects the project to the direction the industry is taking. I exposed the graph to an AI agent through an MCP server, the standard mechanism for giving a model a tool to call. The server provides two tools. The first, where_does_term_come_from, traces a business term back to its source. The second, what_breaks_if_model_changes, reports every model downstream that would break if a given model changed. Both run a fixed Cypher traversal and return rows from the graph.
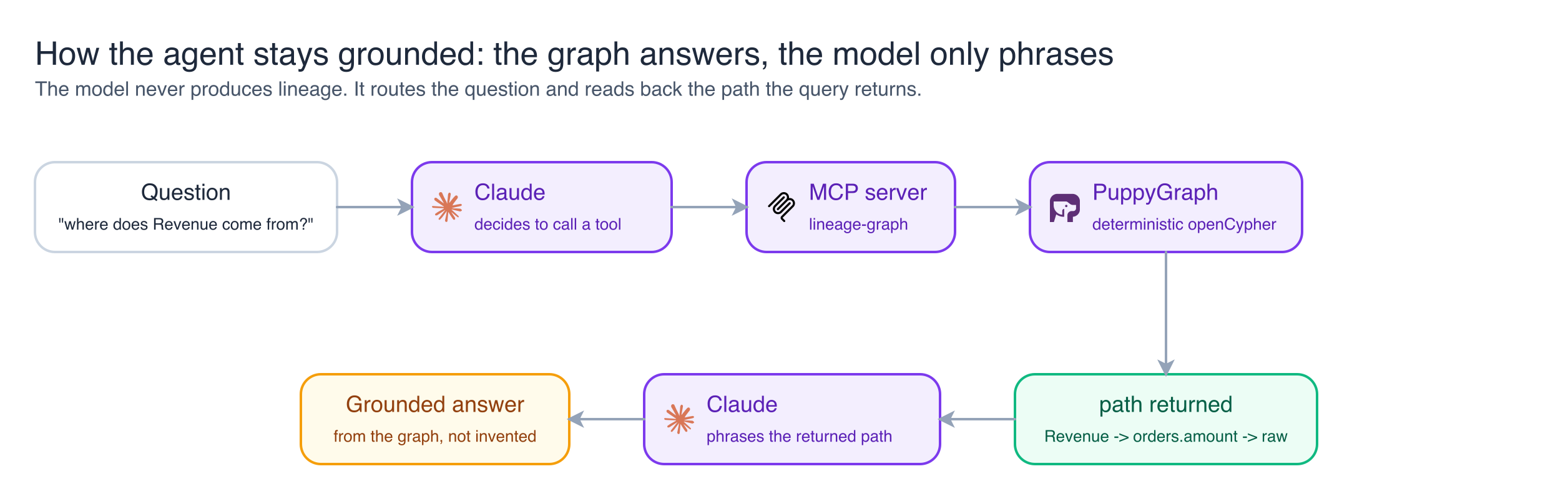
In Claude Desktop, the question is asked in plain language: where does Revenue come from. The model elects to call the tool, the tool executes the deterministic Cypher query in PuppyGraph, and the actual path is returned. The model then renders that path as a sentence. The decisive property is that the model never produces the lineage itself. It routes the question to the tool and reports the result, so the answer is auditable and cannot be fabricated.
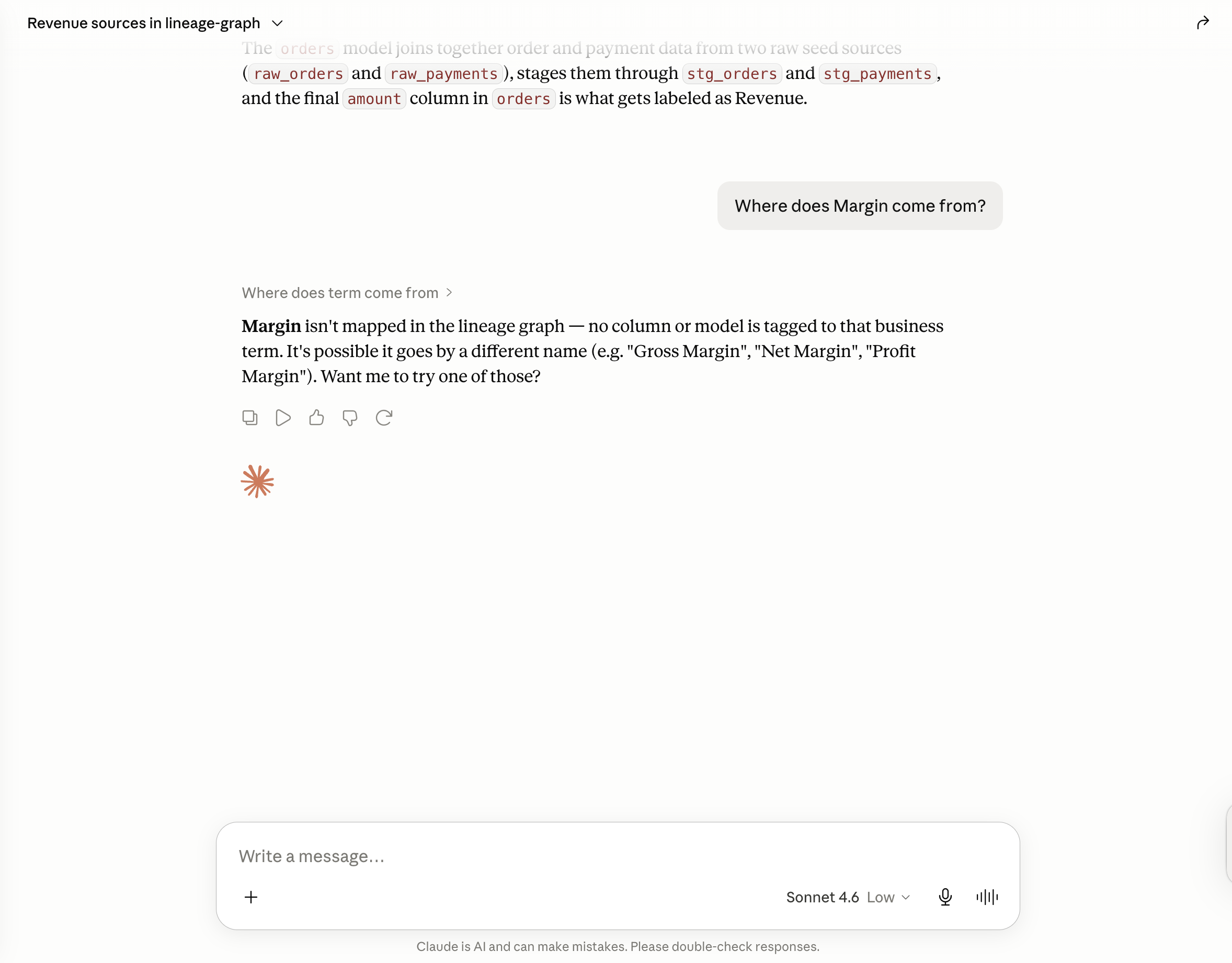
The behaviour that demonstrates this most clearly is the negative case. Ask about a term that is absent from the graph, such as Margin, and the tool returns nothing, so the model states that there is no mapping instead of inventing one. That single behaviour separates an agent that grounds its answers from one that guesses.
Where this fits among related work
The project did not arise in isolation. It is the semantic counterpart to Open Lineage Meets Graph: Observability for the Agentic Lakehouse, a talk by Scott Haines of Databricks and Jaz Ku of PuppyGraph at the Databricks Data + AI Summit. Their pipeline emits OpenLineage events from a Spark plugin at runtime, lands them in Delta and Iceberg, and queries them as a graph with PuppyGraph. Their emphasis is observability, a faithful record of what actually ran. This project takes up the same theme, open lineage met by a graph for the agentic lakehouse, from the opposite end. The lineage here is declared by dbt, the value added is the business term, and the question being answered is what a number means and where it comes from.
One distinction is worth making plainly. This project does not use OpenLineage. The lineage comes from the dbt manifest and Unity Catalog, so I call it open, queryable lineage. That is not the same as OpenLineage, however close the two names sound. OpenLineage is the standard the Haines and Ku talk is built on, and it is exactly the piece this project leaves out.
The project is also clearly informed by Genie Ontology. Databricks recently shipped Genie Ontology, which constructs a living graph of business terms and metrics grounded in governed data, ranks it with an authority score they call ontorank, and surfaces it through Genie chat and agents. It is strong work, and it confirms the underlying premise that a governed graph of meaning is where the field is heading. The capability it does not expose is direct query access to that graph, since it is reachable only through chat and agents, with no public API that returns the nodes and edges. This project is the open, queryable, far smaller cousin of that idea. It lacks the scale, the automatic extraction, and the ranking. What it offers is the one capability otherwise missing, namely that you can run your own query against the graph in the open.
Scope, audience, and limitations
A few clarifications about scope are in order, in the same spirit of candour.
This is a demonstration of a practice, not a finished product. The underlying need, queryable lineage combined with business meaning, is a routine one on any serious data team, whether for impact analysis ahead of a migration, for audit, or for grounding agents. The specific form shown here, openCypher over a small jaffle_shop, is a faithful demonstration of that need rather than something a business user would query directly. The realistic everyday consumer is automation and agents. A continuous integration check could run the impact query and fail a build when a column change would break a certified metric, and an agent could ground its answer on the graph instead of deferring to a closed chat. That is the honest audience for the work.
The lineage itself is not novel. Unity Catalog already performs native column level lineage, and I make no claim to the contrary. The contribution is the composition of governed meaning with provenance into one open, queryable graph, together with an agent grounded in it.
Neither is this a runtime observability system. It reads the declared dependency graph from dbt, not live execution events. The runtime, cross engine, OpenLineage rendering of this theme is the Haines and Ku talk, which is a different and complementary undertaking.
Reproducing the project
The components are unremarkable, which is rather the point. dbt builds jaffle_shop into Unity Catalog. A short parser reads the manifest and the column comments and writes the six metadata tables. PuppyGraph runs as a container, reads those tables over an EXTERNAL USE SCHEMA grant, and serves the graph over Bolt. The agent is an MCP server of two small files that runs the Cypher query and passes the result to the model. Everything is on GitHub.
The objective was modest and specific. Take the governed meaning that Databricks already holds well, take the lineage that dbt already generates well, place both in one graph that anyone can query in the open, and let an agent answer a real question by reading that graph rather than guessing. That much works, and it is a small but honest step toward the agentic lakehouse whose managed version the rest of the industry is now building.