Postgres to ClickHouse CDC for Trade Surveillance
In a trading firm, trades are booked into a transactional database, and Postgres is a common choice for that database. The same trade data is needed by other teams during the day. Risk wants to see updated exposure, surveillance wants to check for unusual activity, and operations wants to confirm that the bookings are clean.
These teams run analytical queries such as total notional by desk, the count of trades under review, and the average risk score across the book. Running such queries on the trading database is not a good idea. They are heavy, they compete with live booking traffic, and a row store like Postgres is not efficient for wide aggregations in the first place. The common approach is to keep a separate analytical copy of the data in a column store such as ClickHouse and point the dashboards at that copy. The open question is how current the copy is. If it is refreshed by a nightly or hourly batch job, the dashboard can be several hours behind the actual book, which is not acceptable for intraday surveillance.
Change data capture, or CDC, keeps the copy current. Instead of reloading the whole table on a schedule, CDC reads each committed change from the database log and applies it to the copy within a few seconds. Artie is a managed service that runs this pipeline for you, so the next section starts with how it works.
How Artie works
Artie splits the work into two parts. A reader subscribes to the source database log, which is the Postgres write ahead log here, and turns each row change into a message. The messages go into a Kafka buffer, with one topic per table keyed by the primary key. A second process, Artie Transfer, reads from Kafka, detects schema changes, and merges the changes into the destination, which is ClickHouse in this case.

Keeping the reader and the writer separate keeps the reader simple. This matters because if the reader stalls, the source log starts to build up on the primary. If the destination is briefly unreachable, the changes wait in Kafka without affecting the source database, and Transfer continues from the last offset once the destination is back.
Artie runs this with exactly-once delivery and sub-minute latency. It applies schema changes automatically, and it does not store your data, since Kafka is only a buffer between the source and the destination. It also handles the parts of Postgres CDC that are easy to get wrong. Large values are stored out of line as TOAST columns, and an unchanged TOAST column is not sent in the log by default, which can corrupt the copy if it is not handled. A replication slot can fall behind and hold log files on the primary if a consumer stalls. The merge into the destination has to be idempotent so that a retry does not double count a change. Artie deals with these, so the data platform team does not have to run a streaming system of its own. The same setup works for other sources such as MySQL, MongoDB, and DynamoDB, and other destinations such as Snowflake, BigQuery, and Redshift.
The rest of this post explains the pattern underneath, using a trade surveillance example built with a plain replication slot and a small worker, so you can see what Artie is doing on your behalf.
The trades table
The source of truth is a trades table. Each row holds the desk, trader, client, venue, symbol, asset class, side, quantity, price, notional in USD, a risk score from 0 to 100, and a status. The status moves through booked, review, approved, blocked, and cancelled as the trade is worked.
The dashboard reads this data and shows open notional by desk, average risk by desk, the number of trades sitting in review or blocked, and the count of high risk trades above a threshold. All of these are aggregations over the full book, which is the kind of query ClickHouse handles well and Postgres does not.
Batch loading
A batch job re-reads the source table on a schedule and reloads the destination. It is simple to set up, but it has three problems for this use case.
The freshness is limited by the schedule. If the job runs every hour, the copy can be an hour behind. An analyst reviewing trades during the day cannot work with data that old.
The cost is tied to the table size, not the number of changes. Most rows in a reload have not changed, so the job moves the entire book to capture a few edits.
Deletes and corrections are awkward to handle. A cancelled trade or a corrected booking has to be reconciled by comparing the old and new snapshots, and that logic tends to drift and produce quiet mismatches.
CDC avoids all three. It moves only the rows that changed, it moves them as they are committed, and it carries updates and deletes as proper events rather than differences that have to be worked out later.
The pipeline
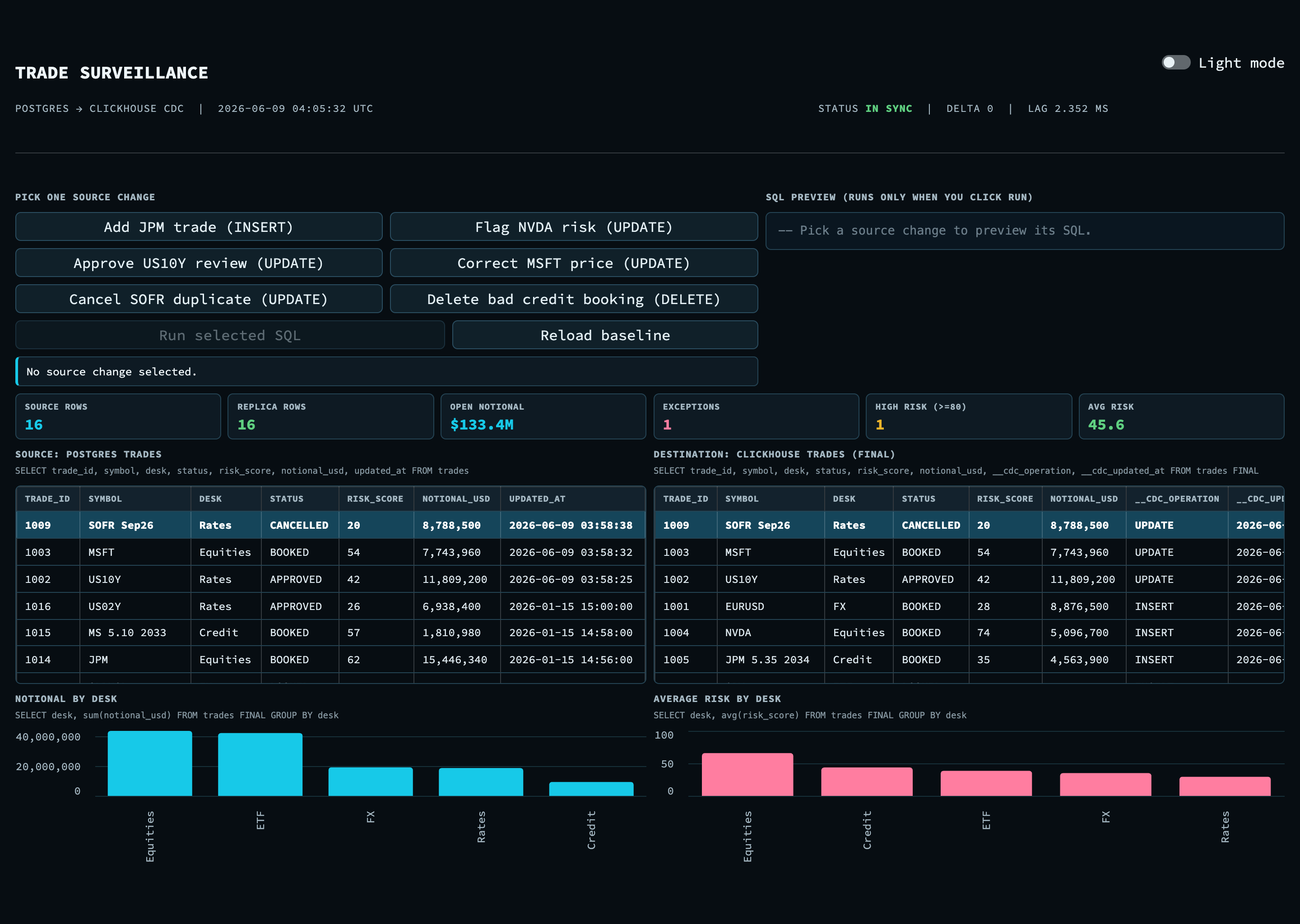
The pipeline is a single line. Trades are booked in Postgres. Each committed change is written to the Postgres log. A consumer reads that log and applies the change to ClickHouse. The dashboard reads from ClickHouse. The dashboard never writes to ClickHouse. It only writes to Postgres, and ClickHouse changes only after CDC has applied the event. This is what makes the freshness something you can verify rather than assume.
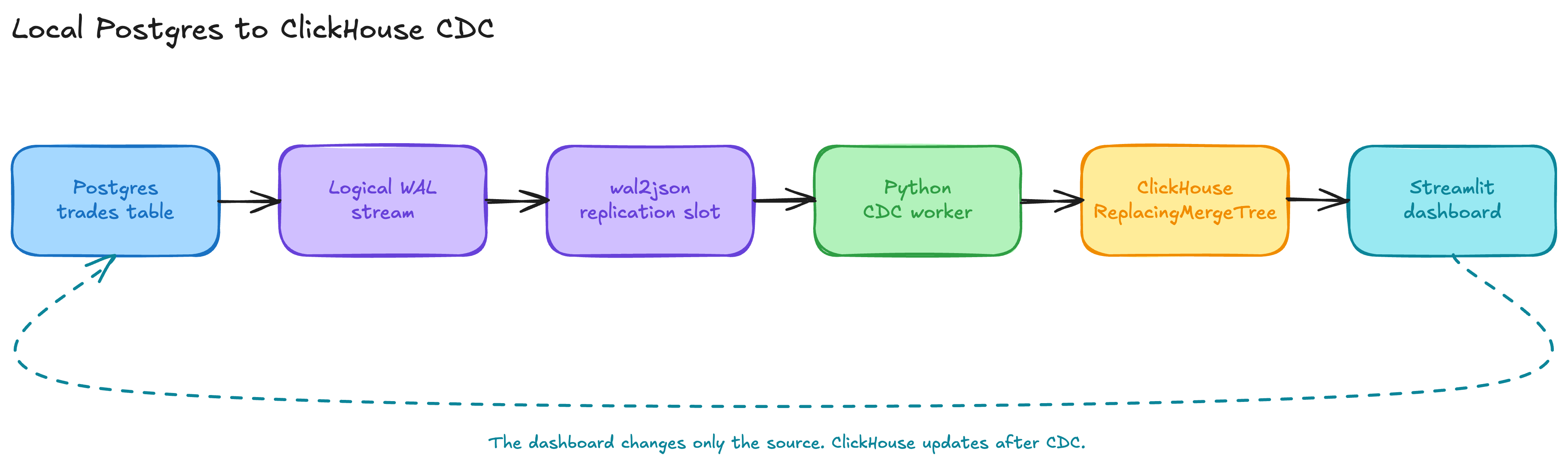
The demo here builds the consumer with a logical replication slot and a small worker. Artie replaces that middle part with the managed reader, Kafka, and Transfer shown earlier. The two sides of the pipeline, Postgres and ClickHouse, work the same way in both cases.
Postgres side
Postgres exposes committed changes through logical replication. A replication slot keeps track of the consumer position in the log and holds back the part of the log that has not been read yet, so a restart of the consumer does not lose any change. Setting the table to REPLICA IDENTITY FULL makes the update and delete events carry the full row rather than only the primary key, which is needed to apply them correctly on the other side.
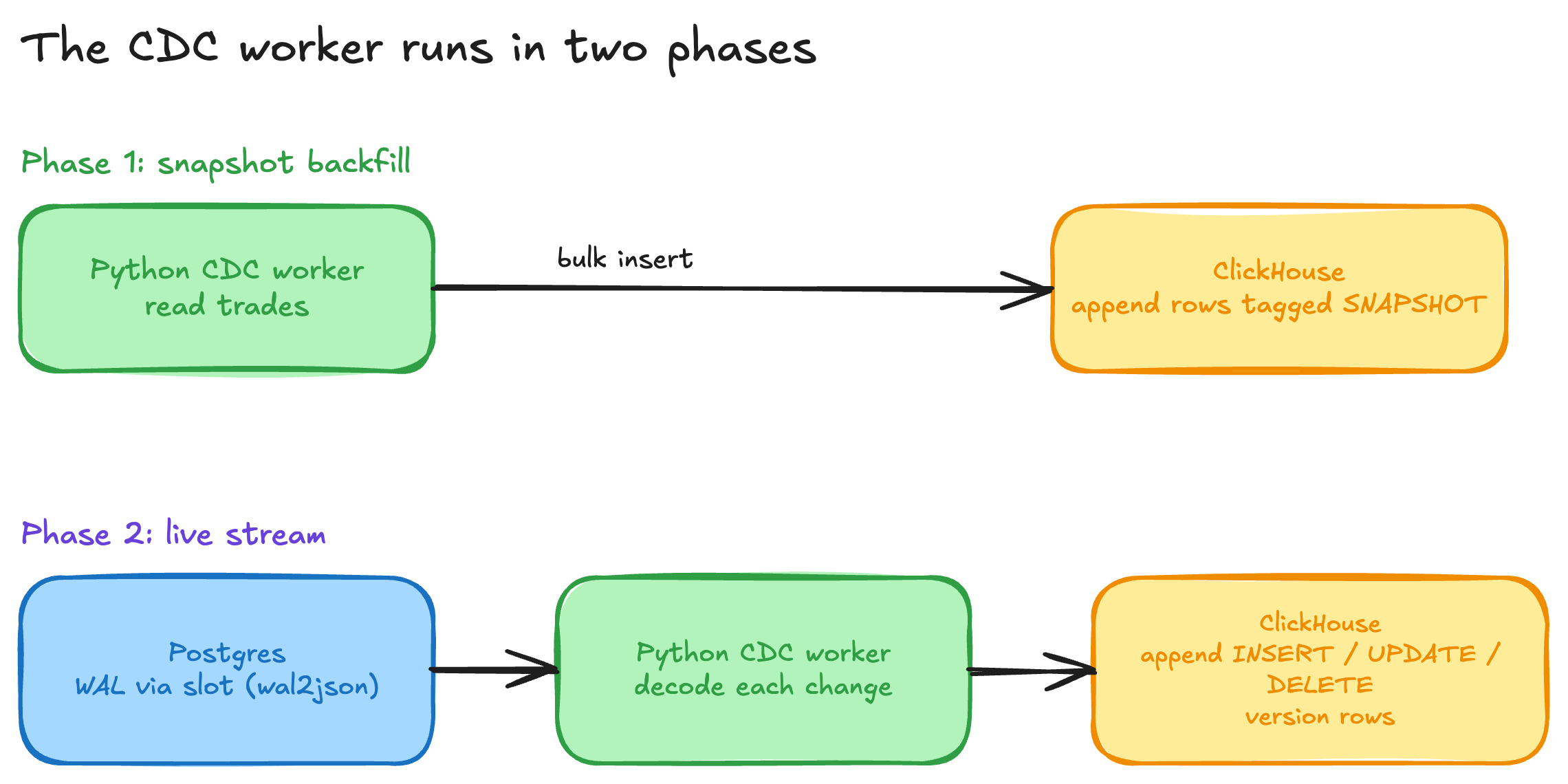
The consumer runs in two phases. It first takes a snapshot of the current table so that ClickHouse starts from a complete state. After that it switches to streaming, where it reads and applies each insert, update, and delete as it is committed.
ClickHouse side
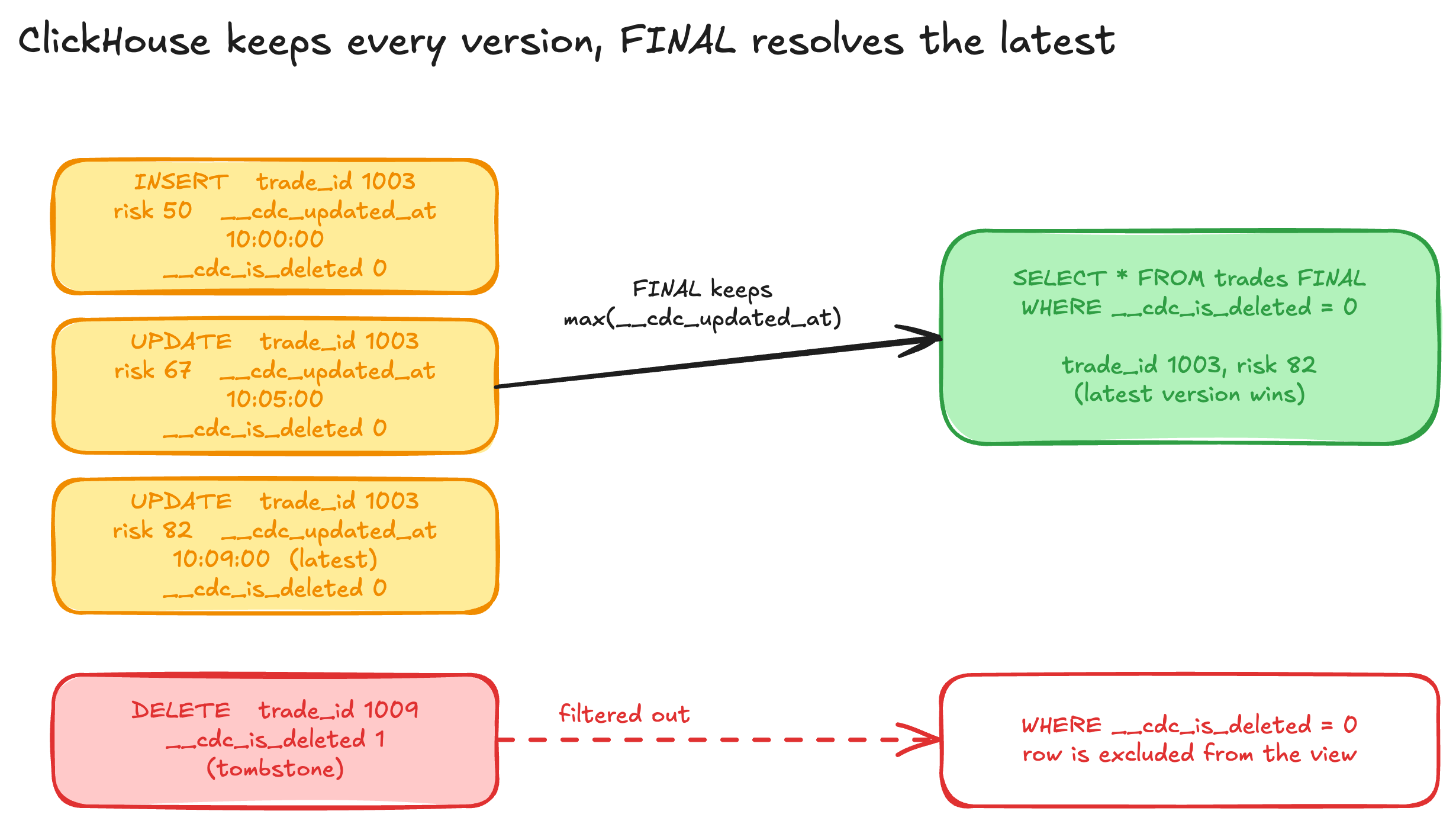
ClickHouse is built for appends and not for updates in place. The practical way to model a table that changes is to append a new version of the row on every change and to resolve the latest version when reading. The ReplacingMergeTree engine does this. Rows are ordered by a key, which is the trade id here, and the engine keeps the version with the highest version timestamp. Each replicated row also carries the operation, a deleted flag for tombstones, and the version timestamp.
CREATE TABLE trades (
trade_id Int64,
...
__cdc_operation String,
__cdc_is_deleted UInt8,
__cdc_updated_at DateTime64(6, 'UTC')
)
ENGINE = ReplacingMergeTree(__cdc_updated_at)
ORDER BY trade_id;
Background merges remove older versions over time. A query can force the same resolution at read time with the FINAL keyword. A delete is stored as a tombstone, so the read filters it out.
SELECT *
FROM trades FINAL
WHERE __cdc_is_deleted = 0
ORDER BY trade_id;
With this approach, an append-only stream still reads as the current state of each trade, including correct handling of updates and deletes.
The worker
The consumer runs in two phases. First it does a snapshot backfill. It reads the entire trades table and inserts every row into ClickHouse tagged with the operation SNAPSHOT. This gives ClickHouse a complete starting state before any streaming begins.
After the snapshot, it switches to streaming. It opens a logical replication slot using the wal2json output plugin and decodes each message as it arrives. For every insert, update, or delete committed in Postgres, the worker appends a new version row to ClickHouse. It never updates in place. Each version carries three bookkeeping columns:
__cdc_operation:SNAPSHOT,INSERT,UPDATE, orDELETE__cdc_is_deleted:0for live rows,1for tombstones__cdc_updated_at: the version timestamp thatReplacingMergeTreeuses to pick the winner
The worker also appends every event to a local cdc_events.jsonl log with a measured lag_ms, so the dashboard can show the most recent CDC events and report the replication lag.
Artie Transfer does the same thing at scale. It reads from Kafka instead of a raw replication slot, handles schema evolution automatically, and guarantees exactly-once delivery so that a retry never double counts a change.
Demo scenarios
The demo maps six buttons to six SQL statements against Postgres. Each one is chosen so that at least one KPI or chart visibly moves once CDC applies the change.
Adding a JPM trade inserts a new equity booking that appears in both tables and raises the total open notional.
Flagging NVDA risk raises the risk score and moves the trade to REVIEW, so the exception count and the risk chart both change.
Approving the US10Y review clears a reviewed rates trade and drops the exception count.
Correcting the MSFT price applies a small price and notional correction that nudges the desk chart.
Cancelling the SOFR duplicate marks a duplicate booking as cancelled while preserving the trade history.
Deleting the bad credit booking removes an erroneous trade entirely, which arrives in ClickHouse as a tombstone and disappears from the FINAL view.
Because the dataset is deterministic, a reload baseline button resets both stores to the same starting point, so the demo is repeatable.
Example
The screenshot below shows the pipeline working from end to end. An analyst applies a price correction to one Microsoft trade. The change is written to Postgres only. Within a few seconds the same trade id shows up at the top of the ClickHouse copy with its operation marked as an update, and the metrics and charts adjust. The source and destination are placed side by side so that the change can be seen moving across.
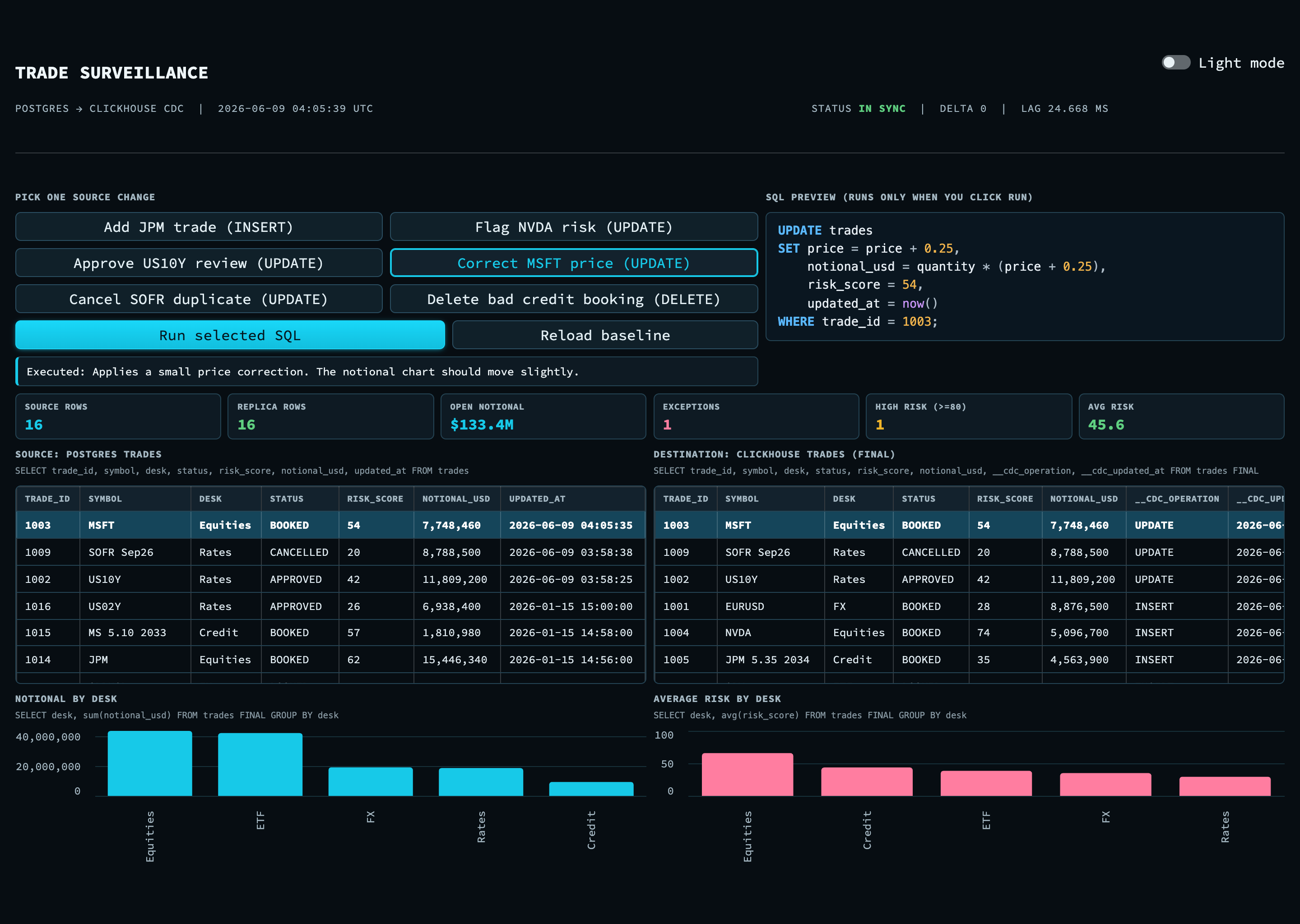
A delete behaves the same way. The trade arrives in ClickHouse as a tombstone and drops out of the FINAL view. When a trade is moved to review, the exception count and the risk chart change. The dashboard stays current within seconds, and the trading database is never touched by an analytical query.
What a production version adds
This demo is a local project, not a platform. The local design keeps the moving parts visible, which is the point. A production build would add the things a single machine demo can skip.
- schema governance and compatibility checks as the source table evolves
- retries, backpressure, and dead letter handling in the worker
- replay controls and slot monitoring so a stuck consumer is caught early
- access controls on both stores and on the dashboard
- lineage and alerting so an analyst trusts what the numbers mean
Artie handles all of these. It monitors the replication slot, retries failed writes with idempotent merges, applies schema changes automatically, and exposes observability so the platform team knows the pipeline is healthy. The core CDC mechanic shown in this post stays the same. Artie hardens it.
FAQ
How current is the data? Changes are usually applied within a few seconds, which gives sub-minute freshness on the analytical side. This is enough for intraday surveillance.
Does this add load to the trading database? CDC reads the log instead of querying the tables, so the analytical work does not compete with live bookings.
How are updates and deletes handled? They are normal CDC events. An update appends a new version that ReplacingMergeTree resolves under FINAL, and a delete becomes a tombstone that the read filters out.
Why ClickHouse? It is suited to the wide aggregations that surveillance and risk dashboards run, and it returns those queries quickly even over a large book.
Why not just use Debezium? Debezium handles the log reading, but you still need to build the merge logic, handle schema evolution, manage Kafka, and monitor the slot. Artie bundles all of that into a managed service with exactly-once delivery.
Summary
A trade surveillance dashboard is only useful if the data behind it is current. A batch load cannot keep up, because it is tied to a schedule and to the size of the table. CDC keeps the ClickHouse copy current by streaming each committed change from Postgres within seconds, and ReplacingMergeTree with FINAL lets an append-only stream read as the latest state of the book.
The pattern underneath is straightforward: a replication slot, a worker that appends version rows, and a merge engine that resolves the latest state. The production work is in the edge cases, TOAST reconstruction, idempotent retries, schema evolution, slot monitoring, and Artie handles those so the data platform team can focus on the analytics instead of the plumbing.
The demo source code is on GitHub if you want to run it locally. To try CDC on your own data with Artie, start with the ClickHouse destination documentation.