One Row Changed in Hudi. The Vector Index Resynced Itself.
Introduction
When working with large scale data pipelines, a common challenge is managing downstream consumers when the source table mutates. For structured queries, Apache Hudi provides an elegant solution. Hudi supports incremental reads out of the box, allowing downstream systems to pull only the changes and stay in sync without rescanning the entire table.
However, the situation becomes more complex with vector indices.
When building a semantic search system on top of a mutable table, the embeddings typically reside in a separate vector store like LanceDB. The moment a record changes in the source table, the corresponding embedding in the vector store becomes stale. Search results end up being served based on text that no longer exists. Many architectures deal with this by scheduling a nightly full rebuild. This works fine until the table grows large enough that re-embedding everything stops being practical.
This project demonstrates a simpler, more efficient approach: leveraging Hudi’s incremental queries to detect precisely which rows changed, and re-embedding just those specific rows in LanceDB.
The full code is available on GitHub, and this post explains the architecture, the implementation, and key technical takeaways.
Reproducing the setup
To run the demo locally, download winemag-data-130k-v2.csv from Kaggle’s Wine Reviews dataset and place it at data/winemag-data-130k-v2.csv. The repo expects that exact path.
LanceDB does not need a separate server in this demo. The Python client creates a local database at lance_db, writes a wine_reviews table, and builds a cosine index over the 384-dimensional vectors.
The Hudi setup is the part that needs Spark. Install the Python dependencies, download the Hudi Spark bundle jar, and keep it under jars/:
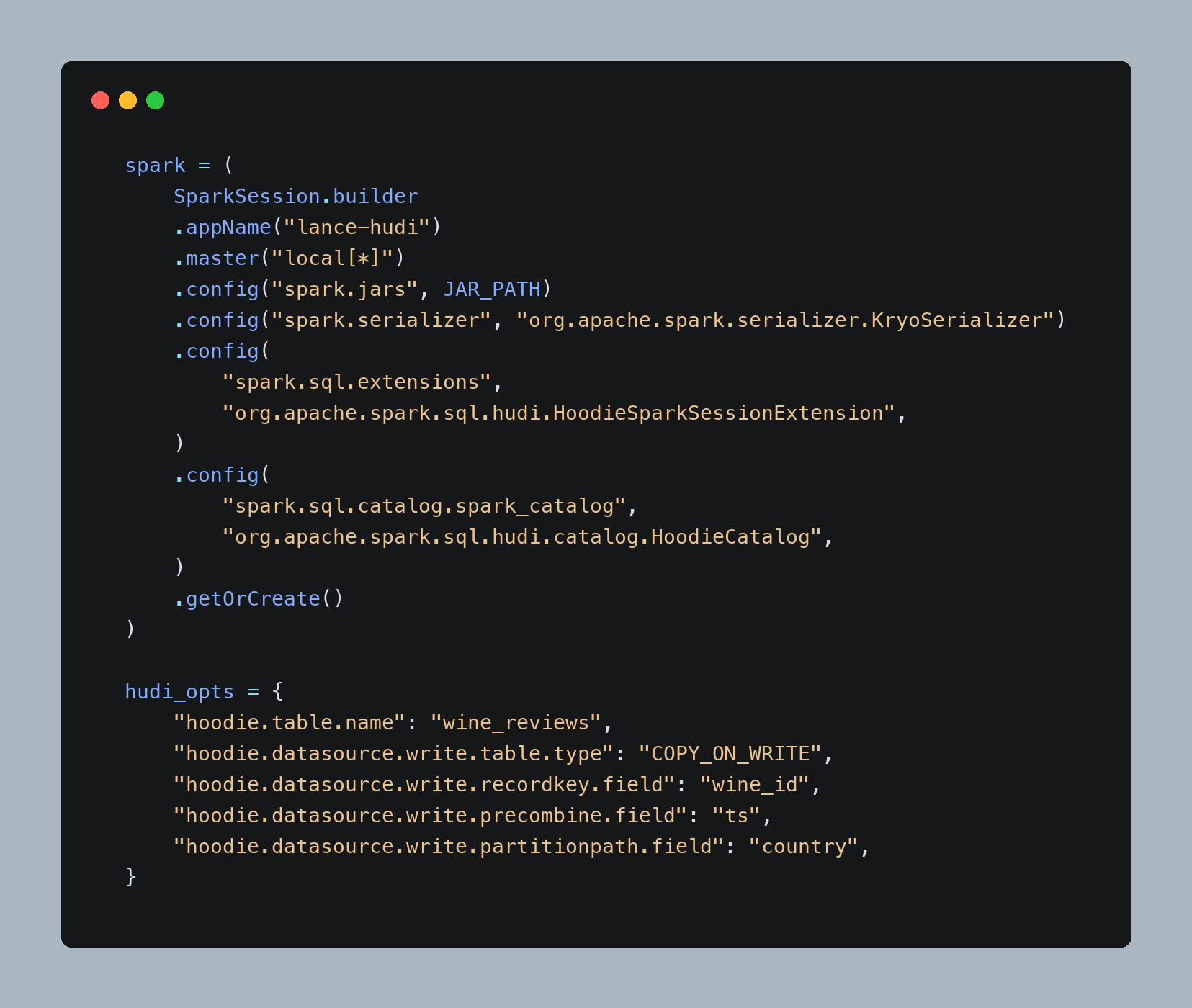
Each script creates a Spark session with the Hudi Spark extension and catalog enabled. The write config uses a copy-on-write table, wine_id as the record key, ts as the precombine field, and country as the partition path.
After that, the run order is 01_ingest_hudi.py, 02_embed_lance.py, 03_demo_sync.py, and 04_poll.py.
The problem worth solving
A vector index is fundamentally a derived artifact. It is built from a source table and remains correct only as long as the source data does not change. In real world scenarios, tables change all the time. Descriptions get corrected, records get updated, and the embedding generated from the old text ends up pointing at a moving target.
The standard industry practice is often a nightly full rebuild, reading every single row to write a completely fresh index. This is perfectly fine for small tables. However, consider a scenario with a hundred million rows where only a dozen records change overnight. Spending compute power to re-embed rows that never moved is wasteful and creates a real bottleneck at scale.
The objective here is narrower: when a single row changes, the system should ideally update just that one row in the index and leave everything else untouched. On an Apache Hudi table, this is straightforward because Hudi meticulously tracks exactly what changed and when. The rest of this post outlines how this synchronization can be achieved.
Architecture
The setup has two stores with a clear hierarchy. Apache Hudi serves as the source of truth, LanceDB acts as a derived index built from it, and a Python sync script (03_demo_sync.py) keeps the two in agreement.
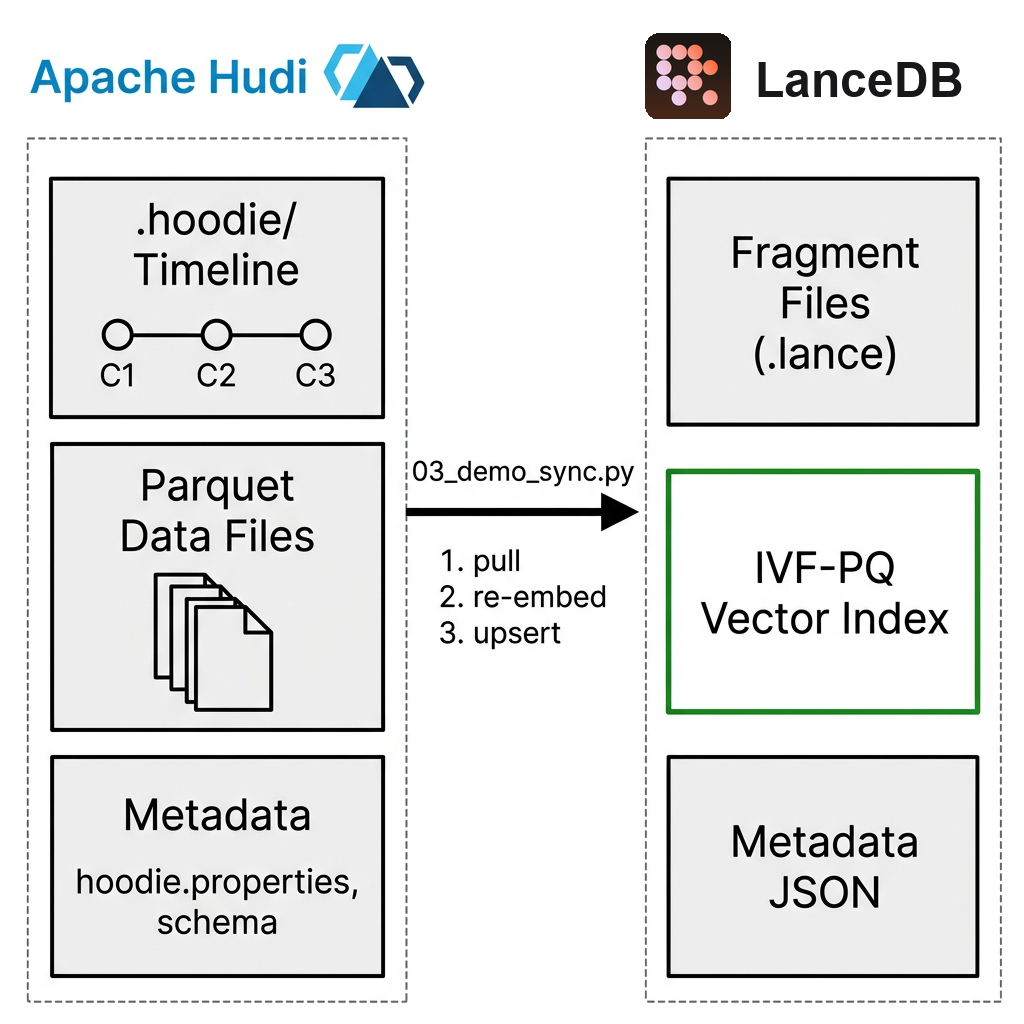
On the Hudi side, the table contains structured fields like country, variety, points, price, alongside the raw description text. On the LanceDB side, there is a 384-dimensional embedding of each description, stored with copies of those same structured fields to allow filtering and searching in a single query. The only component connecting these two stores is the sync script. It runs after a write happens in Hudi, pulls back the exact changes, and patches the index in place.
The Kaggle wine reviews dataset is used for this demonstration, containing roughly 130,000 records. Each wine record has structured columns and one block of free-text description. That description column is embedded, and since it is also the field most likely to be edited or corrected, it serves as a good test case.
Why Hudi
This is where Hudi matters. Apache Hudi is built around change data capture, and this capability makes the entire workflow seamless.
Every write to a Hudi table lands on the table’s timeline as a commit, stamped with a monotonic timestamp. A system can simply query Hudi for incremental changes starting from a given commit, and Hudi will reliably return only the records written after that point. There is no diffing step needed, no separate change-tracking table to maintain, and no full scan required to figure out what moved. Hudi inherently records all of this during the write process.
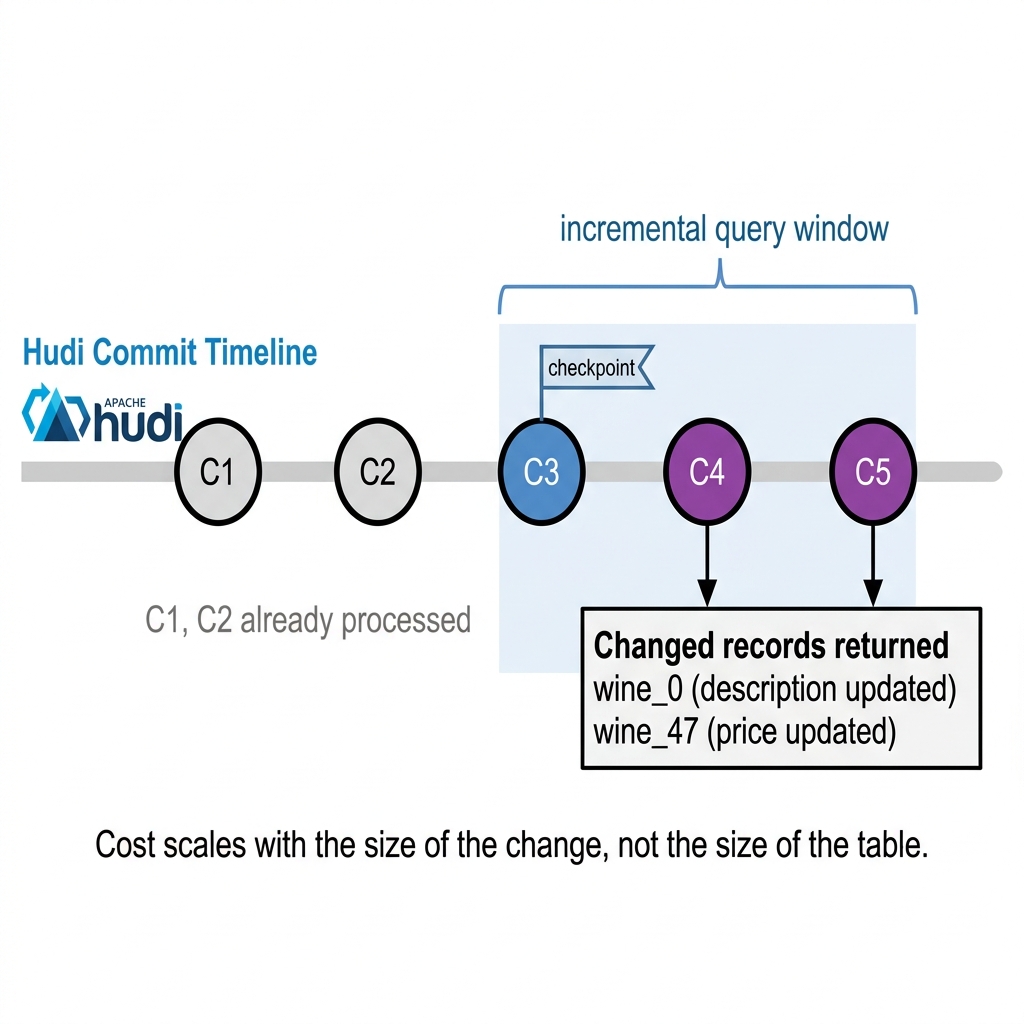
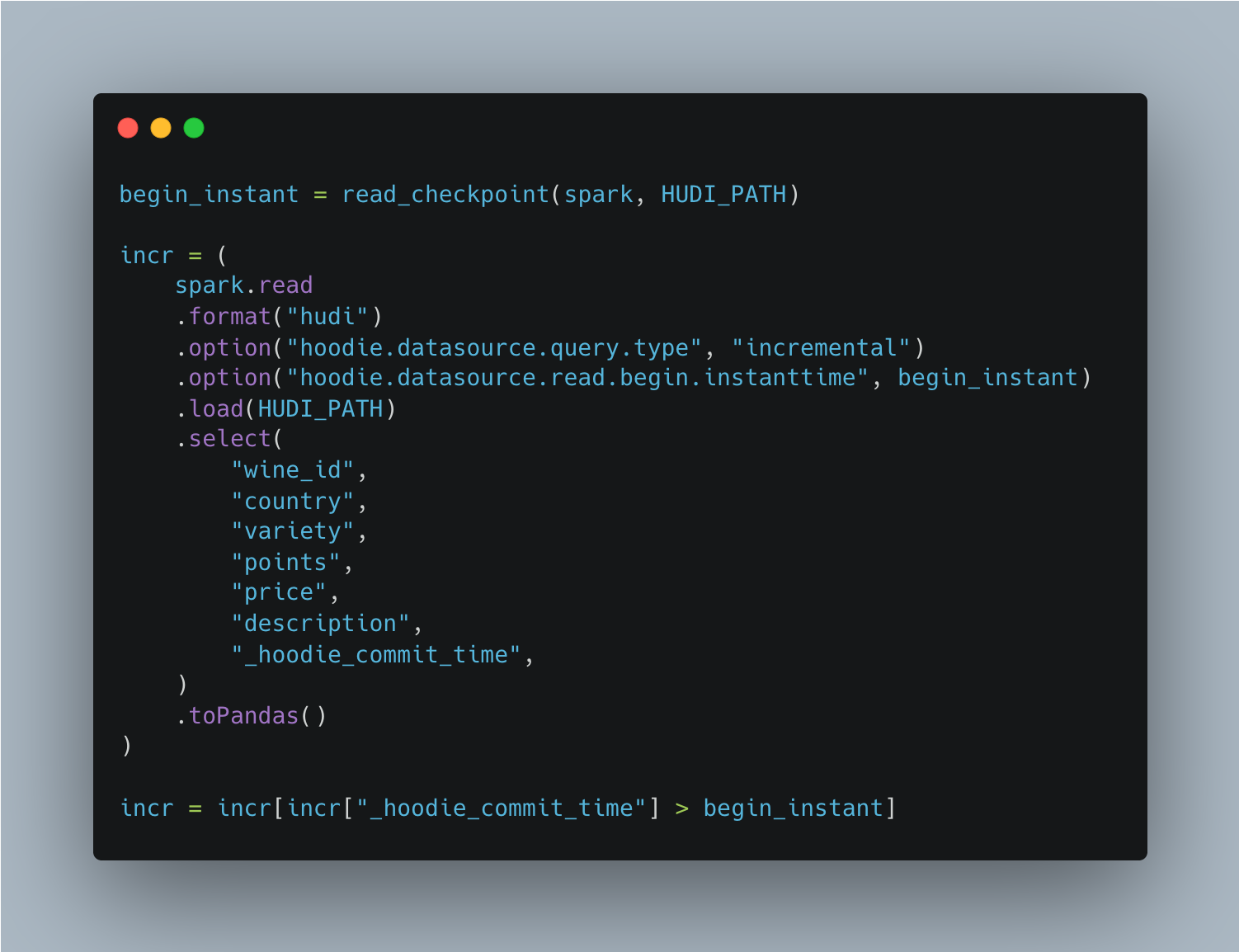
This is what makes the index cheap to maintain. The sync only ever re-embeds the rows that actually changed. The cost scales proportionally with the size of the change rather than the size of the table. On a dataset of 130k records, that distinction is barely noticeable, but on a table with a hundred million rows, it is the difference between a sync you can run continuously and one you simply cannot afford to run at all.
The stack
The write path runs on PySpark 3.5 against a Hudi 1.0.2 copy-on-write table. LanceDB serves as the vector store. Embeddings are generated using sentence-transformers with the all-MiniLM-L6-v2 model at 384 dimensions, and PyArrow handles moving data into LanceDB with explicit column types. The workflow executes as four scripts in sequence.
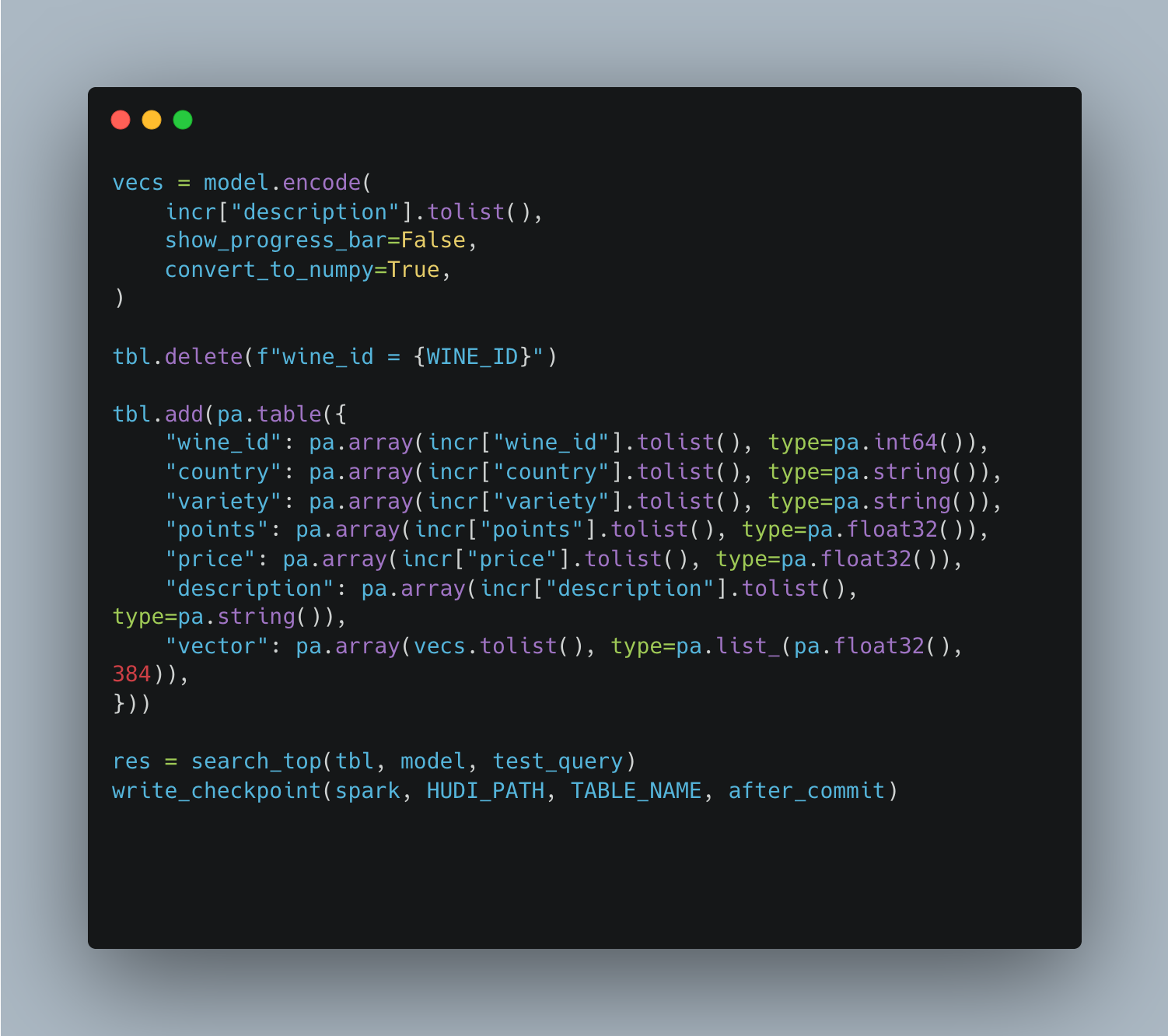
The first script (01_ingest_hudi.py) reads the wine reviews CSV and writes all records into the Hudi table. The second (02_embed_lance.py) reads that Hudi snapshot, embeds every description, and loads the vectors into LanceDB. The third (03_demo_sync.py) is the actual demo: it updates one record in Hudi, detects the change through an incremental query, resyncs LanceDB, and confirms the result with a semantic search. The fourth (04_poll.py) checks the same checkpoint immediately after sync and should find 0 new records.
How the sync works
The mechanism is straightforward. Hudi stamps every data write with a commit timestamp, and the sync script stores its checkpoint in Hudi commit metadata. That checkpoint records the last Hudi data commit LanceDB has processed. On each run, it queries Hudi for everything committed after that checkpoint, re-embeds the descriptions for whatever rows are returned, and then updates LanceDB one record at a time. Only after the LanceDB update and semantic-search verification succeed does it save the latest processed Hudi data commit as the next checkpoint. The following run starts from there, ensuring no commit is ever processed twice and nothing gets missed.
The actual update in LanceDB requires a delete followed by an insert. This is a current constraint of LanceDB. Since there is no in-place vector update API, the only way to replace an embedding is to remove the old row by its ID and then add the new one.
The demo
The demo targets a record wine_0, rewrites its description, and then verifies whether the index successfully noticed the change. Here is the terminal output of the process:
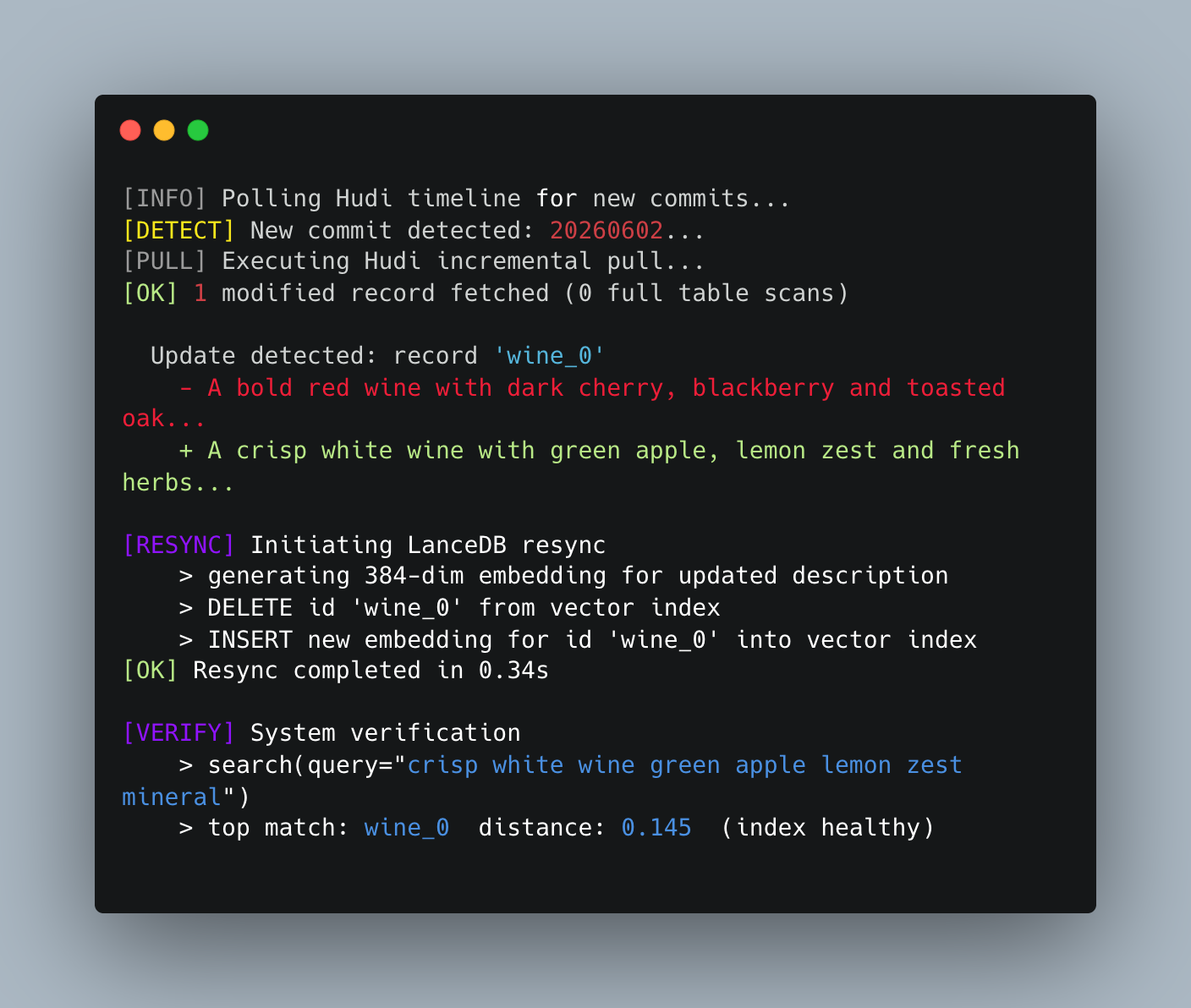
The incremental pull returns exactly one modified record and executes zero full table scans to find it. The stale vector gets deleted, the fresh embedding is inserted, and a subsequent semantic search returns wine_0 at the top with a low distance score. A final poll returns 0 new records, and the index finishes completely consistent with Hudi, without ever needing a full rebuild.
What is next
It is worth noting that this two-store architecture is essentially a bridge. The primary reason a sync script needs to exist is that the vectors live in a separate store from the table they describe. Two upcoming RFCs in the Apache Hudi project are aimed directly at closing that gap.
RFC-100 introduces Lance as a first-class file format inside Hudi, allowing vectors to sit directly in the same table as structured fields. RFC-102 adds native vector similarity search directly on Hudi tables.

Once both capabilities land, the secondary store will stop being necessary altogether. Data will ingest into Hudi, descriptions will be embedded into a vector column on the same table, and semantic search will run against Hudi directly instead of going through a downstream copy. At that point, the entire sync loop will have nothing left to do. The sync script is a stand-in for a capability that Hudi is actively developing, and when it ships, the cleanest version of this project is the one where the script is deleted entirely.
What this is not
A few points are worth clarifying regarding the scope of this project.
This is not a continuously running daemon. Each run processes one batch of changes and then exits. The demo shows a single execution of what would otherwise be a continuous loop. A production version would poll the timeline on a fixed interval and use the same Hudi commit-metadata checkpoint between runs.
It is also reliant on Spark. Hudi 1.0 writes a version 8 table, while alternative runtimes like hudi-rs and Daft currently support up to table version 6. That leaves PySpark as the only viable option for every write.
Lastly, it is not a true in-place update. Because LanceDB does not support updating a vector in place, the sync has to delete the old row and insert a new one. This leaves a brief window where the changed record has no vector in the index at all. For a single-writer proof of concept this is not a concern, but proper handling would be required for concurrent writers.
The goal was to build a working proof of concept to keep a vector index consistent with a mutable Hudi table, without nightly rebuilds and without full table scans. That mechanism works exceptionally well. The full code is on GitHub.