Firebolt, Trino, and Iceberg Pruning Internals
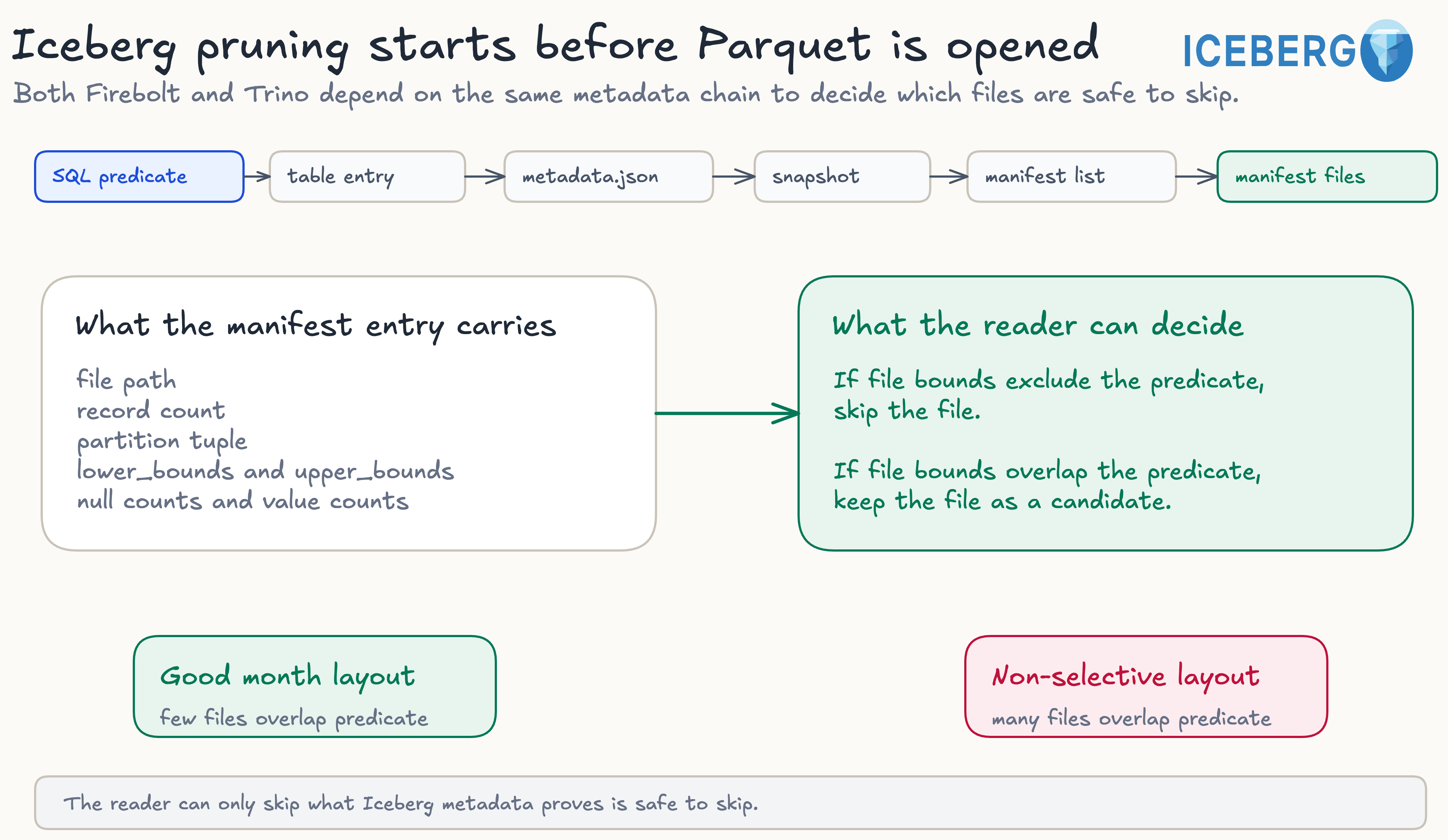
Iceberg query performance starts before any Parquet file is opened. A reader has to resolve the current table state, choose the active snapshot, read the manifest list, inspect manifest files, and decide which data files are safe to skip.
That planning phase is where a simple predicate becomes a cost decision. If the metadata proves that a file cannot contain matching rows, the reader can skip the file. If the metadata only says that the file might contain matching rows, the reader has to keep it as a candidate, even when only a small part of the table is relevant.
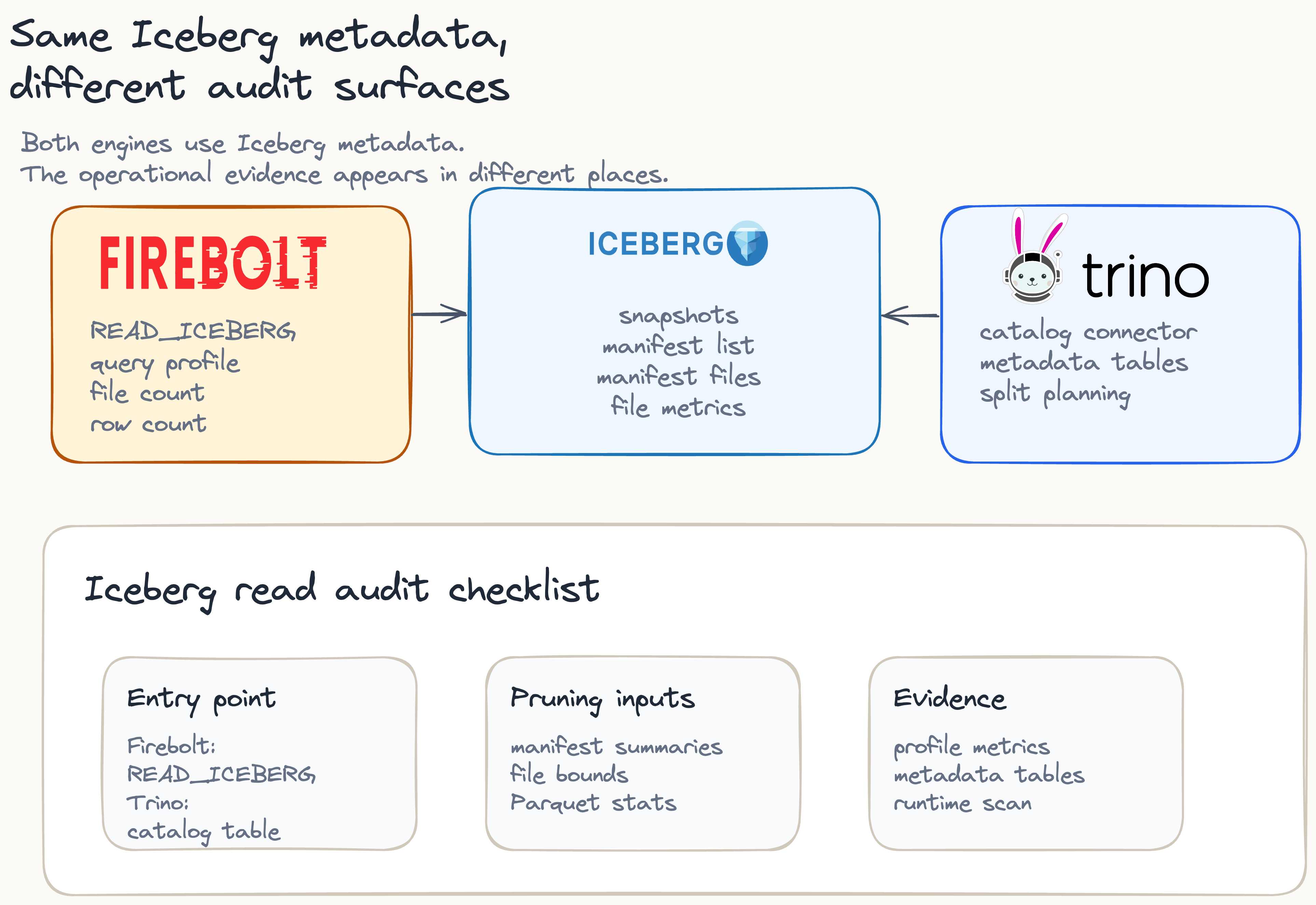
Firebolt and Trino both use Iceberg metadata for this planning work, but they reach the table through different interfaces and expose different audit signals. Firebolt can read an Iceberg table directly through READ_ICEBERG, including a direct pointer to a metadata file. Trino usually reaches the same table through a configured Iceberg catalog and connector.
The important audit question is not only whether the result is correct. It is whether the engine had enough metadata to avoid unnecessary scans. Two reads can return the same count while doing very different amounts of work underneath.
Iceberg Planning Metadata
An Iceberg table is not planned by recursively listing an object-storage directory. The table state is held in metadata files. The current metadata file points to snapshots, the active snapshot points to a manifest list, the manifest list points to manifest files, and the manifest files contain entries for data files and delete files.
For read planning, the important part is the data-file entry in a manifest. It can include the file path, file format, record count, partition tuple, column value counts, null counts, and lower and upper bounds. A reader can compare a query predicate against this metadata before it opens the data file.
The manifest list can help avoid reading every manifest in a snapshot, because it stores partition summaries for each manifest. The manifest file then provides per-file metadata. For a filter such as pickup_month = '2023-03', a reader can skip a file only when the manifest metadata proves that file cannot contain matching rows.
Iceberg metadata can be correct but not selective. A file whose lower bound is January and upper bound is April is correctly described, but a March predicate cannot rule it out, so the reader keeps it as a candidate.
Firebolt Read Path Through READ_ICEBERG
Firebolt reads Iceberg tables through the READ_ICEBERG table-valued function. The function can use a LOCATION object or individual parameters. For file-based catalogs, the URL can point to a table path or directly to a specific metadata.json file. Firebolt also supports REST catalog reads through the same function.
SELECT count(*)
FROM READ_ICEBERG(
URL => 's3://bucket/path/to/table/metadata/v3.metadata.json',
MAX_STALENESS => INTERVAL '30 seconds'
)
WHERE pickup_month = '2023-03';
The direct metadata-file form is useful for audits because it removes catalog ambiguity. The query reads the table state represented by that exact metadata file. In normal repeated access, a LOCATION object is cleaner because it centralises credentials and catalog configuration.
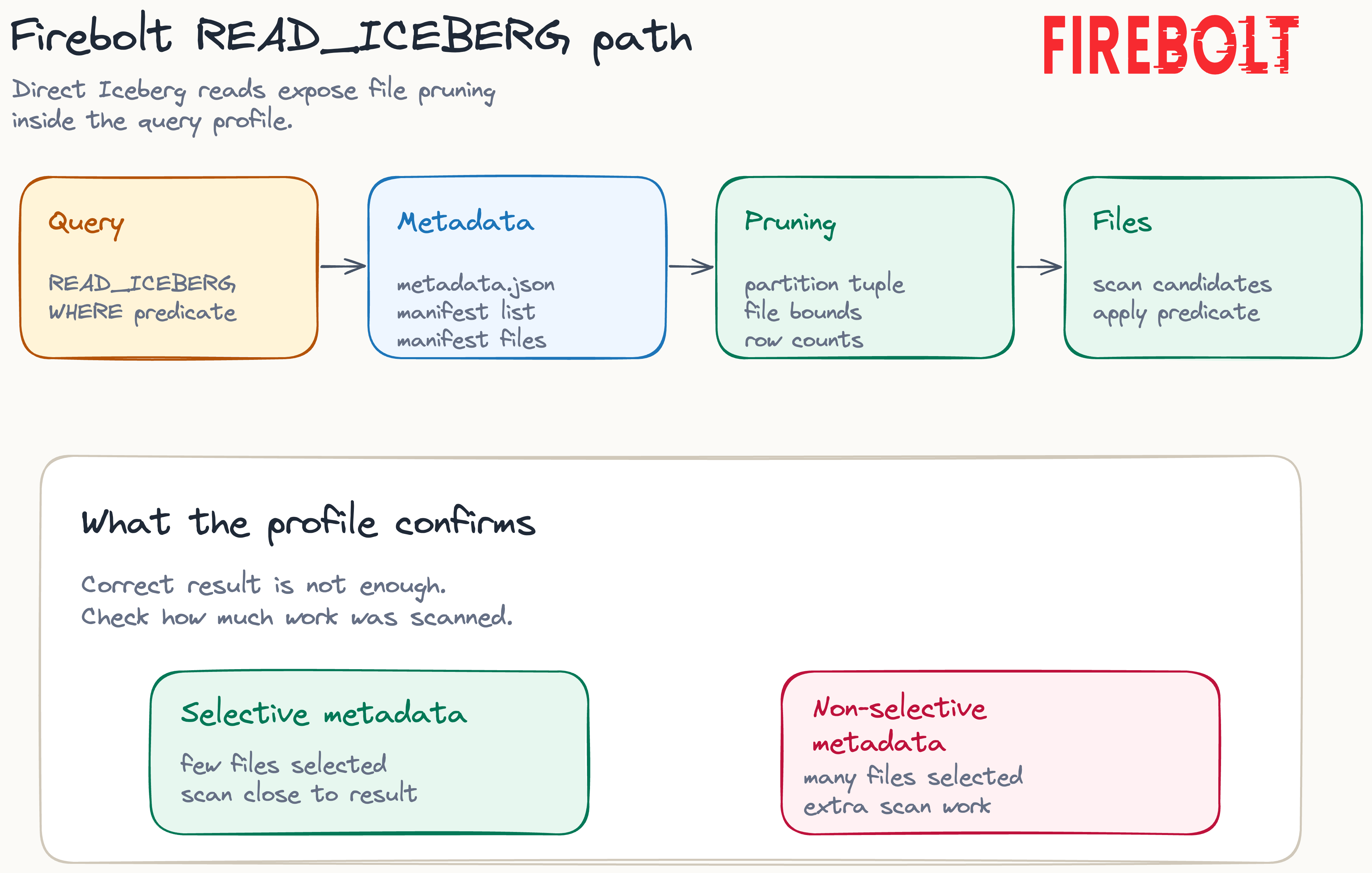
Firebolt’s Iceberg path has a few properties relevant to audit work. It can use manifest-level row counts for optimiser decisions and can answer some aggregation queries such as a plain COUNT(*) without opening data files at all. MAX_STALENESS provides caching control, avoiding repeated catalog and metadata round trips when slightly stale snapshots are acceptable. The path supports two pruning layers: file-level pruning from Iceberg manifest metadata, then Parquet row-group pruning when the row-group statistics are useful. Firebolt’s managed-table primary indexes are a separate storage path and play no role in a READ_ICEBERG scan.
The practical Firebolt audit signal is the gap between files listed and files selected, followed by rows scanned and rows returned. A correct count alone does not show whether file pruning worked. A profile that shows four files listed and one selected tells a different story from a profile that shows four listed and four selected, even if both queries return the same final count.
Trino Iceberg Connector Planning
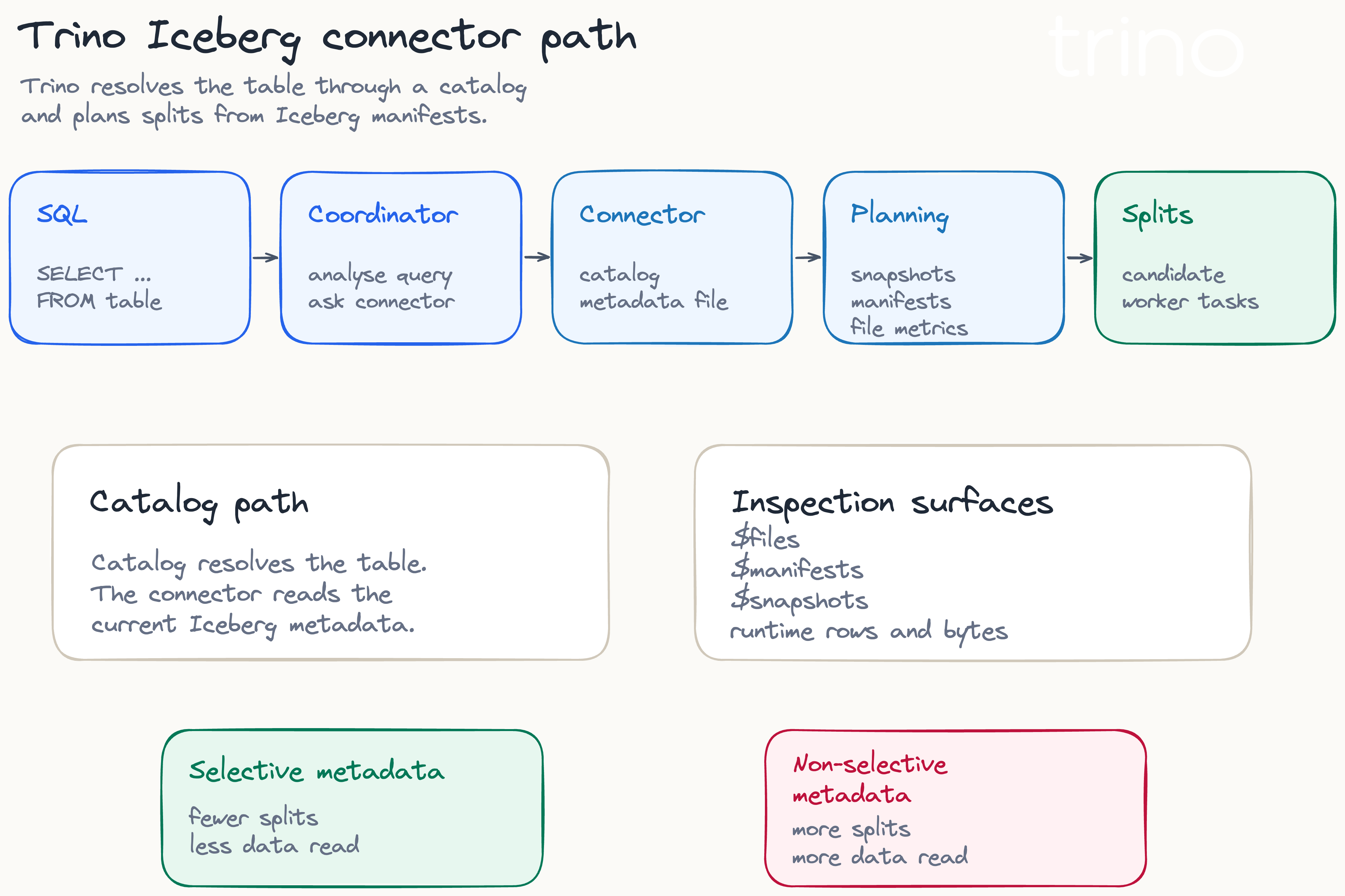
Trino reads Iceberg through the Iceberg connector. Instead of placing a table-valued function in every query, the table is normally resolved through a configured catalog. Trino supports multiple catalog backends for Iceberg, including Hive metastore, AWS Glue, JDBC, REST, Nessie, and Snowflake catalogs.
Once the catalog resolves the table, the connector reads the Iceberg metadata for the current table state and plans work from the files recorded in it. Unlike older Hive-style planning, Iceberg tracks data-file paths directly in metadata, so Trino does not have to list every file in the underlying object-storage directories to discover table contents.
For an existing Iceberg table, Trino can also register the table into a metastore when the register-table procedure is enabled:
CALL iceberg.system.register_table(
schema_name => 'lakehouse',
table_name => 'customer_orders',
table_location => 's3://bucket/path/to/customer_orders',
metadata_file_name => '00003-...metadata.json'
);
That registration step is a workflow difference, not a pruning difference. Firebolt can point directly at a metadata file inside READ_ICEBERG. Trino usually makes the table addressable through a catalog name and schema, after which normal SQL can query it as a table.
Trino is also convenient for metadata inspection. The Iceberg connector exposes metadata tables such as $snapshots, $manifests, $partitions, and $files. The $files table is especially useful when checking whether manifest entries contain the expected record counts, lower bounds, upper bounds, file paths, and manifest locations.
File Layout Decides Metadata Pruning
The read path has three practical pruning layers:
| Layer | What it can skip | Where the signal comes from | Notes |
|---|---|---|---|
| Manifest planning | manifests that cannot match a partition predicate | manifest-list partition summaries | Helps when manifests are clustered around useful partition values. |
| File pruning | entire data files | manifest entries, partition tuple, lower bounds, upper bounds | Where most Iceberg file skipping actually happens. |
| Row-group pruning | row groups inside selected Parquet files | Parquet row-group statistics | Only useful when files have multiple row groups and useful min/max locality. |
Both engines implement both layers. Firebolt’s READ_ICEBERG path uses Iceberg manifest metadata for file skipping, then Parquet row-group statistics where useful. Trino’s Iceberg connector pushes the same predicate into manifest planning first, then into the Parquet reader for row-group skipping.
The writer layout decides how valuable this metadata is. If a writer creates files where each file holds one month, a March predicate can eliminate January and February files. If the writer creates files where every file contains rows from January through April, every file’s bounds overlap March and the reader has to keep them.
A correct Iceberg table can still be expensive to read, because correct metadata and selective metadata are not the same property. Correct metadata says a file might contain matching rows. Selective metadata proves a file cannot, which is the only case where the reader can skip it.
What To Inspect In Firebolt And Trino
A pruning audit has to separate correctness evidence from scan evidence. The final row count proves that the query returned the expected result. The selected-file count, scanned-row count, metadata tables, and split planning signals explain how much work the engine had to do to reach that result.
| Audit question | Firebolt | Trino |
|---|---|---|
| How is the table addressed? | READ_ICEBERG with URL, LOCATION, or REST catalog parameters. | Catalog-backed table name through the Iceberg connector. |
| Can a specific metadata file be targeted? | Yes, by passing a file-based URL ending in metadata/{version}.metadata.json. | Yes, for registration workflows through metadata_file_name when register_table is enabled. |
| What is the main pruning surface? | Iceberg manifests for file pruning, then Parquet row groups where useful. | Iceberg manifests during connector planning, then file-format reader behaviour during execution. |
| What is easiest to inspect? | Query profile shape: files listed, files selected, rows scanned, rows returned. | Metadata tables such as $files, $manifests, $snapshots, plus query output and plan/profile signals. |
| What should not be inferred? | External Iceberg scans are not the same as Firebolt managed-table primary-index pruning. | A second-reader validation is not a speed benchmark. |
Validation: Same Rows, Different Scan Shape
A controlled validation used one cleaned NYC Yellow Taxi dataset for January to March 2023 and exposed it as three Iceberg-readable table shapes. The same March predicate returned 3,403,619 rows in all three cases. The scan shape changed because the file layout changed.
| Case | Final rows | Firebolt scan shape | Trino cross-check |
|---|---|---|---|
| Native Iceberg, month layout | 3,403,619 | 4 files listed, 1 selected, 3,403,619 rows scanned | Not required for baseline |
| XTable over Hudi COW, month layout | 3,403,619 | 4 files listed, 1 selected, 3,403,619 rows scanned | 3.4M rows processed |
| XTable over Hudi COW, mixed layout | 3,403,619 | 4 files listed, 4 selected, 9,384,433 rows scanned | 9.38M rows processed |
XTable-generated Iceberg metadata preserved the file-level statistics that the engines needed. In the month layout, those statistics were selective, so the March predicate selected one file. In the mixed layout, those statistics were still correct, but every file overlapped the March predicate, so all files remained candidates.
That result is useful because it separates metadata preservation from physical layout. A translator can preserve the metadata it is given. It cannot make mixed source files selective without rewriting the data.
Operational Takeaways
For Firebolt users, READ_ICEBERG is a direct way to read Iceberg metadata and check pruning behaviour. Use LOCATION objects for repeatable production queries, consider MAX_STALENESS where slightly stale snapshots are acceptable, and inspect profile evidence when validating scan cost. Treat managed-table indexing as a separate storage path, not as part of an external Iceberg scan.
For Trino users, the Iceberg connector gives a catalog-oriented path into the same metadata. Use metadata tables to inspect snapshots, manifests, partitions, and files. When registering externally created Iceberg tables, be explicit about the metadata file if the catalog cannot infer the intended version.
For anyone writing or translating Iceberg tables, the most important lesson is about layout. File-level bounds are only useful when files have locality. Partitioning, sorting, clustering, file sizing, and row-group sizing decide whether a predicate can become a cheap metadata decision or a broad file scan.
Iceberg readers can skip only what the metadata proves is safe to skip.
References
- Firebolt documentation:
READ_ICEBERG - Firebolt documentation: Iceberg and External Data
- Trino documentation: Iceberg connector
- Trino engineering blog: Just the right time date predicates with Iceberg
- Apache Iceberg specification: Manifests and manifest lists